
AI 音樂製作的真實面貌及本指南的適用對象
想像一下,輸入像「帶有溫暖鋼琴和弦和柔和雨聲的歡快 Lo-fi Hip-Hop 曲目」這樣的句子,然後在 30 秒後聽到一首完成的音樂作品。這就是最簡單形式的AI 音樂製作。但大多數人誤解的一點是:輸出成果的質量取決於您提供的創意方向。AI 並不會取代音樂品味、編曲決策,或判斷某樣東西是否恰到好處的聽覺敏感度。它加速了從擁有想法到讓想法成真的技術步驟。
當今 AI 音樂製作的實際樣貌
那麼,AI 音樂在實踐中是如何運作的呢?核心在於,經過海量音頻數據訓練的機器學習模型會學習旋律、節奏、和聲和音色中的模式。當您提供文本提示或一組參數時,它們會根據這些學習到的模式生成新的音頻。結果並非複製現有歌曲,而是由您的輸入引導的、基於統計信息的創作。將其視為音樂的自動完成功能,而非從庫中提取內容的点唱機。
LANDR 最近的一項研究發現,87% 的製作人已在工作流程中的某個環節使用 AI 驅動的工具,其中 66% 將它們創造性地應用於歌曲創作、旋律或人聲。這項技術已不再處於實驗階段。它已成為音樂製作標準的一部分。然而,超過 40% 的受訪者同樣標註了對輸出質量和倫理的擔憂,這告訴我們一些重要的事情:這些工具功能強大,但需要深思熟慮的使用和現實的期望。
根據您的創意目標找到您的路徑
閱讀本指南的每個人想要的東西並不相同。您的起點以及與您最相關的部分取決於您試圖創建的內容:
- 需要節拍和背景音樂的內容創作者 — 您希望為 YouTube 視頻、播客或社交媒體快速獲得版權清晰的曲目。專注於第 2、4 和 5 步,以最快速度獲得可用的音頻。
- 希望製作完整歌曲的準詞曲作者 — 您頭腦中有歌詞或旋律,但沒有製作經驗。第 3、4 和 5 步將引導您從零開始進行基於提示詞的歌曲創作。
- 探索 AI 音樂商業應用的企業家和營銷人員 — 您需要了解許可、變現和發行。第 6 和 7 步涵蓋版權、平台條款以及將曲目上架到串流服務。
每條路徑都有重疊之處,閱讀完整指南將使您受益。但了解您的主要目標有助於您優先考慮首先在哪裡投入精力。
在本指南結束時您將完成的目標
這本 AI 音樂製作初學者逐步指南將帶領您從零知識走向發布曲目。在最後一部分,您將設置一個功能齊全的工作空間,為您的目標選擇合適的工具,學習如何編寫有效的提示詞,創建和編輯一首完整的歌曲,了解法律環境,並將您的音樂發行到串流平台。這是其他資源在單一 walkthrough 中無法提供的從第一天到完成的弧線。
這裡的語調是誠實的:AI 音樂工具確實令人印象深刻,但它們不是魔法。您仍然需要做出創意決策、批判性地評估輸出成果並完善您的結果。技能重心從演奏樂器轉向了有效地指導 AI,而這種技能就像任何其他技能一樣,需要練習。
您的第一個決定是務實性的。在生成任何內容之前,您需要正確的設置。硬件要求可能比您預期的要低,但一些具體細節很重要。
第 1 步:設置您的工作空間並了解基礎知識
AI 音樂製作實際上需要什麼樣的電腦?答案可能比您想像的要求更低。由於大多數AI 音樂生成器在雲端運行,繁重的處理發生在遠程服務器上,而不是您的本地機器上。您的電腦主要需要處理網頁瀏覽器、基本音頻播放和輕量級編輯軟件。話雖如此,某些規格比其他規格更重要,提前了解它們可以避免日後的問題。
最低硬件和互聯網要求
音樂製作中人工智慧的核心要求歸結為三件事:處理器速度足夠快,能流暢運行現代瀏覽器;有足夠的 RAM,可同時開啟多個分頁和音訊編輯器;以及穩定的互聯網連接,以便從基於雲端的工具串流傳輸音訊回來。
根據 MusicRadar 的硬件建議,您至少需要 Intel i5 或 AMD Ryzen 5 處理器(或同等級的 Apple M1)、Windows 系統需 16GB RAM 或 Mac 系統需 8GB 統一記憶體,以及用於儲存的 SSD。不過,針對 AI 音樂,您的互聯網頻寬與本地規格同樣重要。在雲端生成曲目並串流傳輸結果回來需要可靠的連接,下載速度理想情況下應為 10 Mbps 或更快。
| 規格 | 最低要求 | 建議配置 |
|---|---|---|
| 處理器 | Intel i3 / AMD Ryzen 3 / Apple M1 | Intel i5 / AMD Ryzen 5 / Apple M2 或更新版本 |
| RAM | 8GB(Windows 系統需 16GB) | 16GB 或更多 |
| 儲存空間 | 128GB SSD,具備 20GB 可用空間 | 256GB 或以上 SSD |
| 互聯網速度 | 5 Mbps 下載速度 | 10+ Mbps 下載速度 |
| 作業系統 | Windows 10 / macOS 12 / ChromeOS | Windows 11 / macOS 14+ |
好消息是:如果您在過去四五年內購買了電腦,您可能已經符合最低要求。基於雲端的 AI 工具會承擔計算密集型工作,因此即使是普通的筆記型電腦或迷你 PC 也可以作為您的工作站。如果存在瓶頸,真正的瓶頸往往是緩慢或不穩定的互聯網連接,而非您的硬件。
了解音訊格式和質量設定
當您生成第一首曲目並點擊匯出按鈕時,您將會遇到一些可能看起來陌生的文件格式選項。了解基本知識可以防止您意外降低音訊質量或將錯誤的文件類型上傳到平台。
您最常看到的三種格式是 WAV、MP3 和 FLAC。正如 What Hi-Fi? 所解釋,這些格式根據其處理壓縮的方式分為不同的類別:
- WAV — 未壓縮音訊。這是最高質量的格式,沒有數據損失,但文件較大(CD 質量下每分鐘約 10MB)。當您計劃進一步編輯或混音您的曲目時,請使用 WAV。
- MP3 — 有損壓縮音訊。文件較小且普遍兼容,但部分音訊數據會被永久丟棄。在 320kbps 下,對於隨意聆聽而言,質量損失極小。在 128kbps 下,您會注意到明顯的下降。
- FLAC — 無損壓縮音訊。它將文件大小減少至 WAV 的大約一半,而不犧牲任何質量。這是存檔已完成曲目或分發到支持該格式的平台的良好選擇。
您還會遇到兩個關鍵數字:採樣率和位元深度。採樣率(以 kHz 為單位)描述了每秒捕捉多少個音訊快照。CD 質量為 44.1 kHz,許多 AI 工具以 48 kHz 匯出,這是視頻的標準。位元深度(16-bit 或 24-bit)決定了動態範圍。對於初學者來說,44.1 kHz 和 16-bit 對於串流傳輸來說完全足夠,而如果您計劃稍後編輯文件,48 kHz 和 24-bit 會為您提供更多的餘量。
開始之前應安裝的免費軟件
您的大部分 AI 音樂創作都是在基於瀏覽器的工具中進行的,但有一些免費程序可以完善您的工作空間,用於編輯和潤飾:
- Audacity — 一款免費的開源音訊編輯器,適用於 Windows、macOS 和 Linux。使用它可以修剪靜音、調整音量、淡入淡出,或將多個 AI 生成的片段拼接在一起。它原生支持 WAV、MP3 和 FLAC。
- VLC Media Player — 無需編解碼器即可播放幾乎任何音訊格式。對於快速預覽不同格式的匯出文件非常有用。
- Google Chrome 或 Firefox — 大多數基於雲端的 AI 音樂工具都針對基於 Chromium 的瀏覽器進行了優化。保持瀏覽器更新以獲得最佳的兼容性和音訊播放性能。
在開始生成音樂之前安裝這些軟件。準備好 Audacity 意味著您可以立即載入 AI 生成的曲目,修剪開頭,標準化音量,並以您需要的確切格式重新匯出。它彌合了原始 AI 輸出與準備上傳的 polished 文件之間的差距。
配置好工作區並釐清音訊格式的基礎知識後,下一個問題便是該將瀏覽器指向哪些 AI 工具。生成器、節拍製作器和人聲工具的選擇範圍比大多數初學者預期的更廣,若為目標選錯類別,只會浪費本可用於創作的時間。
步驟 2:明智選擇您的 AI 音樂工具
您已準備好工作區並了解音訊格式。接下來的決定將影響後續一切:您實際要開啟哪種工具?2026 年最佳的 AI 音樂生成器分為不同的類別,為創作目標選錯類型,就像需要合成器時卻買了鼓機。每類工具解決的問題不同,在註冊任何服務前先了解這些差異,可避免您在各個平台之間遊走卻無法完成任何一首曲目。
AI 音樂工具的類型及各自適用時機
AI 音樂領域並非單一產品類別,而是四個重疊的類別,每個類別專為製作流程的不同階段或不同類型的輸出而設計。以下是其分類方式:
- 文字轉歌曲生成器 — 您輸入描述流派、情緒、速度和樂器編制的提示,工具便會生成包含人聲、樂器和編曲的完整歌曲。這是從零到完成音訊的最快途徑。適合希望立即獲得成果、無需先學習製作概念的初學者。
- AI 節拍製作器 — 專注於器樂循環、鼓點模式和節奏基礎。製作人使用這些工具生成原始素材,然後在數位音訊工作站(DAW)中進行分層和編排。最適合想要建構模組而非成品歌曲的創作者。
- AI 人聲工具 — 生成歌唱人聲、和聲或聲音克隆,您可將其疊加在現有的器樂軌上。當您有節拍但無人聲歌手,或希望獲得多語言人聲而不必聘請錄音室歌手時,這類工具非常實用。
- AI 混音和母帶處理助手 — 這些工具並非從頭生成音樂。相反,它們透過調整均衡器(EQ)、壓縮、立體聲寬度和響度以符合串流平台標準,來完善您已有的作品。請將它們視為最後一步,而非起點。
對於正在學習如何開始 2026 年初學者 AI 音樂製作的人士而言,文字轉歌曲生成器的入門門檻最低。您無需具備任何樂理知識、DAW 經驗,除了瀏覽器外也無需其他設備。隨著工作流程日益成熟,並開始在單一專案中結合多種工具時,其他類別才會變得相關。
| 工具類別 | 使用案例 | 所需技能等級 | 典型輸出品質 |
|---|---|---|---|
| 文字轉歌曲生成器(例如 MakeBestMusic、Suno、Udio、ElevenLabs Music) | 從文字提示生成完整歌曲,包括人聲和編曲 | 適合初學者,無需音樂知識 | 高 — 完整製作,許多流派達到電台播放水準 |
| AI 節拍製作器(例如 Sonura、Soundful) | 器樂循環、鼓點模式和節拍基礎 | 對歌曲結構有基本了解會有幫助 | 中至高 — 節奏元素強烈,可能需要編排 |
| AI 人聲工具(例如 ElevenLabs Voice、ACE Studio) | 歌唱人聲生成、和聲、多語言人聲 | 中級 — 需要現有器樂軌進行搭配 | 支援的語言和風格品質高 |
| AI 混音助手(例如 LANDR、iZotope Ozone AI) | 潤飾、母帶處理、響度優化 | 具備基本混音詞彙會有幫助 | 專業級母帶處理輸出 |
如果您的目標是盡快從構想到完成歌曲,請從第一行開始。MakeBestMusic 的 AI 音樂生成器在此是一個強大的起點,因為其提示和風格工作流程讓您能用通俗語言描述所需內容、選擇音樂風格,並在不觸及任何製作控制項的情況下獲得完整歌曲。對於希望從概念到可播放軌道達成最快速徑的初學者來說,這種簡易性比您尚未使用的高級功能更為重要。
免費方案與付費方案的比較及實際獲得的內容
AI 音樂生成的定價並非一目了然。大多數平台採用基於點數的系統,每次生成歌曲會消耗一定數量的點數,而您的方案決定了每月可獲得的點數數量。免費層級與付費層級之間的差距不僅僅在於數量——這通常決定了您是否可以合法地將輸出內容用於商業用途。
根據 Chartlex 的驗證比較,以下是 2026 年頂級 AI 音樂生成工具的定價概況:
- 免費層級通常每天提供 3 到 10 次生成機會。它們非常適合實驗和學習提示詞技巧,但大多數完全限制商業使用。ElevenLabs Music 的免費方案每天最多提供 7 首歌曲,而 Suno 則提供 50 個每日點數(約 10 首歌曲),但不具備商業權利。
- 入門付費方案(每月 $8 至 $15)解鎖商業權利並顯著增加您的每月輸出量。每月 $10 的 Suno Pro 提供 2,500 個點數(約 500 首歌曲),而每月 $9.99 的 ElevenLabs Pro 則提供 500 首曲目。對於希望發布作品的初學者來說,這是最佳選擇。
- 高級方案(每月 $24 至 $49)添加高級功能,如分軌導出、更長的生成長度、優先處理和更高的音頻質量。每月 $30 的 Suno Premier 包含一個名為 Suno Studio 的全 AI 原生數字音頻工作站(DAW)。每月 49 歐元的 AIVA Pro 授予您對生成的每首曲目的完整版權所有權。
大多數初學者忽略的關鍵細節:幾乎所有平台上的免費層級都明確禁止商業使用。如果您計劃將曲目上傳至 Spotify、將 YouTube 視頻變現或出售伴奏,您至少需要一個入門付費方案。在發布任何通過免費帳戶生成的內容之前,請務必閱讀服務條款。
每首曲目的成本也各不相同。在基於點數的系統中,單次歌曲生成可能會根據長度和複雜度消耗 5 到 10 個點數。按照 Suno Pro 的費率計算,這相當於每首歌曲約 $0.02。按照 AIVA Standard 的費率,每次下載的成本接近 $1。根據您的需求量不同,經濟效益會有巨大差異。
如何為您的第一個項目選擇合適的工具
面對數十種選項,您如何縮小範圍並確定一個起點?問自己三個問題:
- 您想要一首完整的歌曲還是構建模塊?如果您想要一首可以立即發布的成品曲目,請選擇文本轉歌曲生成器。如果您想要原始素材以便在數字音頻工作站(DAW)中自行編排,請關注支持分軌導出的 AI 節奏製作工具。
- 您需要人聲嗎?並非所有工具都能生成演唱內容。Stable Audio 和 AIVA 僅生成純音樂。如果人聲對您的項目至關重要,您需要使用 Suno、Udio、ElevenLabs Music 或 MakeBestMusic。
- 您第一個月的預算是多少?如果答案是零,請從免費層級開始,以學習提示詞技巧並評估輸出質量。一旦您知道哪個平台能產生您喜歡的結果,隨時可以升級。如果您能花費 $10,這將立即開通商業權利和更高的生成限制。
對於本指南的大多數讀者來說,建議很簡單:從提供免費或低成本入門點的文本轉歌曲生成器開始,學習提示詞如何轉化為音樂輸出,僅在遇到特定限制時才擴展到其他工具。試圖同時掌握四個不同的平台會導致注意力分散,無法完成任何音樂作品。
從一個工具開始。完成一首曲目。然後根據您希望第一個工具能以不同方式實現的功能來擴展您的工具庫。
2026 年最佳的免費 AI 音樂生成器都讓您可以在沒有財務承諾的情況下進行實驗。利用這段時間培養對優質聲音的鑑賞力,了解哪些提示詞風格能產生讓您產生共鳴的結果,並在承諾付費方案之前建立信心。您的支出應跟隨平台與您的創意方向一致的證明,而非 precede it(先於它)。
選擇工具只是方程式的一半。另一半,即將平庸的输出與讓您真正自豪的曲目區分開來的部分,在於您如何與這些生成器進行溝通。提示詞的質量決定了音樂的質量,而大多數初學者低估了這項技能的重要性。

步驟 3 掌握提示詞工程以獲得更好的 AI 音樂
您的 AI 音樂工具已準備就緒。您已選擇了一個平台。您輸入「製作一個酷炫的節奏」並點擊生成。返回的結果聽起來……千篇一律。平淡無奇。與您脑海中的想法不符。這正是大多數初學者陷入困境的時刻,而這與工具本身無關。令人失望的输出與您真正想使用的音樂之間的差距,歸結為一項技能:如何為 AI 歌曲生成器編寫更好的提示詞。
AI 音樂模型以機率方式解讀您的文字。它們將描述性語言對應到已學習的音樂模式,而您選擇的字詞會直接影響哪些模式被啟動。模糊的指令會產生模糊的音樂。具體、結構化的提示則能產生聚焦且符合流派風格的結果。學習 AI 音樂的提示工程(prompt engineering)是初學者可以培養的最高槓桿技能,因為它無需成本、不需要任何設備,並且能立即改善您生成的每一首曲目。
優質 AI 音樂提示的構成要素
一個建構良好的提示並非願望清單或情緒板。它是一組結構化的音樂指示,用以減少隨機性並引導 AI 朝向特定的聲音。根據 Sonygram 的提示工程研究,AI 模型會對早期的 token 賦予較高的權重,這意味著您提示中的前五到十個字會強烈影響整個輸出的流派方向。放在開頭的内容最重要。
這個能持續產生可靠結果的通用公式遵循以下順序:
情緒 + 流派 + 樂器編制 + 調性/音階 + 速度/BPM + 編曲結構 + 製作風格
每個組成部分在縮窄 AI 創作空間方面都有獨特的作用:
- 情緒 — 設定和聲走向與旋律樂句。像「憂鬱」、「振奮」、「緊張」或「懷舊」等詞彙告訴模型音樂應傳達的情感氛圍。
- 流派 — 定義節奏結構、樂器使用規範及整體聲音識別。由於它為其他元素奠定基礎,請將此項置於提示的開頭附近。
- 樂器編制 — 要具體。「Rhodes 電鋼琴」比「鋼琴」產生更好的結果。「刷奏鼓組」與「鼓組」會給您不同的輸出。您越精確,模型需要猜測的部分就越少。
- 調性/音階 — 小調引入張力與情感。大調創造明亮感與解決感。指定「D 小調」或「G 大調」能穩定整首曲目的和聲進行。
- 速度/BPM — 數值化的 BPM 錨定節奏網格。若沒有它,模型會根據流派機率估計速度,這可能導致不穩定的律動或非預期的節拍。
- 編曲結構 — 像「16 小節主歌進入 8 小節副歌」或「在第 33 小節 buildup 至 drop」這樣的結構指示,告訴模型如何組織段落,而非無限循環。
- 製作風格 — 像「溫暖類比飽和度」、「乾淨數位母帶處理」或「寬廣立體聲場」等描述詞塑造最終的聲音特徵。
以下是實際應用中的差異。針對同一個創意構想,模糊提示與結構化提示的對比:
模糊:「做一個 chill 的 lo-fi beat。」結果:通用的鼓組循環、隨機的鋼琴、缺乏連貫感。
具體:「A 小調、78 BPM 的憂鬱 lo-fi hip-hop,帶有黑膠爆豆聲的 dusty swing 鼓組、Rhodes 電鋼琴和弦、溫暖的低音貝斯線、16 小節無縫循環、柔和類比飽和度。」結果:連貫、符合流派風格且可直接使用的循環。
具體的提示使用了七個不同的音樂參數。每一個參數都消除了一層隨機性。AI 無需猜測速度、調性、鼓組音色或結構。您已定義了創作邊界,模型則在這些邊界內填充細節。
真正有效的流派與情緒描述詞
並非所有描述性詞彙在 AI 音樂生成中具有同等權重。有些描述詞過於抽象,模型難以從音樂角度解讀;而其他詞彙則直接對應到訓練過的模式,能產生一致的結果。了解哪些詞彙有效可避免您浪費生成次數。
用於 AI 音樂生成的最佳提示使用基於音樂特徵的描述性語言,而非純粹的主觀感受。「Energetic(充滿活力)」很有用,因為它對應到較快的速度和推進感的節奏。「Cool(酷)」幾乎沒用,因為它沒有 consistent 的音樂詮釋。
以下是能可靠產生更好輸出的描述詞類別:
- 有效的速度詞彙 — driving(推進感)、laid-back(懶散放鬆)、bouncy(彈跳感)、punchy(有力)、hypnotic(催眠感)、relentless(不懈)。這些詞彙對應到模型可以執行的特定節奏行為。
- 有效的情緒詞彙 — melancholic(憂鬱)、euphoric(愉悅亢奮)、tense(緊張)、atmospheric(氛圍感)、nostalgic(懷舊)、triumphant(凱旋)。每個詞彙都暗示了獨特的和聲與旋律走向。
- 應避免的情緒詞彙 — nice(不錯)、cool(酷)、good(好)、interesting(有趣)、beautiful(美麗)。這些是主觀判斷,而非音樂指示。
- 樂器具體性 — 使用「supersaw lead(超級鋸齒波領奏)」而非「synth(合成器)」,使用「fingerpicked acoustic guitar(指彈原聲吉他)」而非「guitar(吉他)」,使用「808 glide bass(808 滑音貝斯)」而非「bass(貝斯)」。儀器名稱前的形容詞能大幅縮窄聲音調色盤。
給初學者的一個關鍵 AI 音樂提示工程技巧:避免矛盾的描述詞。在單一提示中結合「dark(黑暗)、happy(快樂)、energetic(充滿活力)、slow(緩慢)」會使模型困惑,因為這些術語指向相反的音樂方向。輸出結果會變得混亂而非富有創意。選擇一致的情感路線,并使用相互強化的描述詞。
你也不需要成為音樂理論專家。如果你不知道該選擇什麼調式,可以嘗試使用「小調」來營造情感豐富或黑暗的音效,使用「大調」來營造明亮或令人振奮的音效。如果你不確定 BPM(每分鐘拍數),可以使用以下一般範圍:放鬆的曲目使用 70 到 90,中速節奏使用 90 到 120,充滿活力或適合舞曲的音樂使用 120 到 150。
如何迭代和優化你的提示詞
即使是結構良好的提示詞,也很少能在第一次生成時產生完美的結果。學習如何使用 AI 創作音樂的真正技巧在於迭代優化:批判性地聆聽、識別需要改變的地方、調整特定的描述詞,然後重新生成。這反映了專業提示詞工程師在所有 AI 領域的工作方式,並直接適用於音樂生成。
每次生成曲目時,請遵循此流程:
- 第一次生成時從廣泛開始。使用通用公式,並根據你對情緒、流派、BPM 和樂器配置的最佳猜測進行填寫。不要過度思考。第一次輸出的目的是診斷,而非最終結果。
- 聆聽輸出並識別一兩個具體問題。 tempo 是否太快?鼓聲是否過於激烈?旋律是否感覺沒有方向?情緒是否不對?首先選擇最重要的問題。
- 僅調整相關的描述詞。如果鼓聲太重,將「有力的鼓聲」改為「刷奏鼓聲」或「輕柔的打擊樂」。如果節奏感覺太急,將 BPM 降低 10 到 15。一次更改一個變量可以讓你知道每個描述詞實際控制的是什麼。
- 重新生成並比較。將新輸出與上一個版本一起聆聽。這次更改是否在解決問題的同時沒有產生新的問題?如果是,則轉向下一個問題。如果不是,則為同一元素嘗試不同的描述詞。
- 記錄有效的方法。當你找到一個能產生你喜欢內容的提示詞時,請將其保存起來。建立一個按流派和情緒組織的個人提示詞模板庫。隨著時間推移,這個庫會變得越來越有价值,因為你不再需要從零開始。
初學者常見的一個錯誤是重新生成完全相同的提示詞,希望獲得更好的結果。AI 生成包含隨機性,因此你有時可能會偶然獲得更好的輸出。但是,根據你聽到的內容故意更改特定單詞進行 deliberate refinement(刻意優化),比隨機重新滾動產生更一致的良好結果。
另一個錯誤是一次更改太多變量。如果在聆聽一次後重寫整個提示詞,你就無法識別哪些更改改善了輸出,哪些使輸出變差。將每次生成視為受控實驗:一次更改,一次觀察,然後決定下一步行動。
將提示詞優化想像成調整相機鏡頭焦距。每次微小的調整都會讓圖像更加清晰。你不會在每次拍攝後更換鏡頭——而是進行精確、漸進的旋轉,直到主體清晰為止。
大多數 AI 音樂模型的理想描述詞範圍是四到七個核心元素。少於四個會讓模型擁有過多自由度,導致輸出_generic_(普通/泛泛)。超過七個可能會稀釋信號,導致模型難以處理衝突或過於詳細的限制。找到那個甜蜜點,讓你的提示詞足夠具體以產生聚焦的結果,同時足夠靈活,允許 AI 在你定義的邊界內進行創意生成。
掌握了提示詞結構和優化的堅實基礎後,自然的下一步就是將這些知識應用於真正的曲目中。理論只能帶你走到這裡。當你在即時生成器中輸入第一個提示詞並聽到返回的內容時,本節中的每個概念都會豁然開朗。
步驟 4 創建你的第一首完整的 AI 生成歌曲
你已經理解了提示詞結構。你知道哪些描述詞對應哪些音樂行為。但是,閱讀關於提示詞的內容與實際在即時生成器中輸入提示詞是兩種不同的體驗。這正是學習加速的地方。在接下來的幾分鐘內,你將從空白屏幕過渡到一首完全可以聆聽、評估和優化的完整製作歌曲。以下是逐步創建你的第一首 AI 生成歌曲的確切方法。
從文本提示詞創建你的第一首曲目
在本次演練中,我們將使用 MakeBestMusic 的 AI 音樂生成器 作為演示平台。其提示詞和風格的工作流程反映了你在上一節中學到的通用公式,使其成為立即應用這些技能的理想場所。其界面足夠簡潔,讓你不會迷失在菜單中,但又足夠靈活,讓你的提示詞能夠真正控制輸出。
請按照以下由帳戶建立到完成曲目的逐步 AI 歌曲創作流程:
- 建立您的帳戶。前往 makebestmusic.com/app/create-music-new 並註冊。整個過程只需不到一分鐘。登入後,您將直接進入創作介面。
- 輸入您的提示詞。使用步驟 3 中的公式輸入結構化描述。對於您的第一首曲目,可以嘗試類似以下的內容:「G 大調、112 BPM 的振奮人心獨立流行樂,明亮的原聲吉他掃弦,溫暖的女聲演唱,輕快的鈴鼓和軍鼓節奏,懷舊的夏日氛圍,主歌-副歌-主歌-副歌結構。」這為 AI 提供了七個清晰的參數以供處理。
- 選擇您的風格參數。選擇與您的提示詞相符的流派或風格預設。如果平台提供情緒或樂器選項,請利用它們來強化您的文字描述,而非與其矛盾。將這些選擇視為在您書面提示詞之上的第二層指導。
- 如有歌詞請添加。如果您希望人聲包含特定歌詞,請將歌詞貼入歌詞欄位。如果您尚未準備好歌詞,可以讓 AI 根據您的情緒和主題描述生成歌詞。這兩種方法都能產生完整的人聲軌道。
- 生成曲目。點擊建立並等待。大多數生成過程在兩分鐘內完成。AI 會解讀您的提示詞,構建編曲,生成樂器和人聲,並交付一首完整長度的歌曲。
- 完整聆聽輸出內容,不要中斷。克制跳過或提前停止播放的衝動。您的第一次聆聽應是被動的——吸收整體感覺、能量以及各段落之間的流動。您在分析細節之前,先形成直覺印象。
- 第二次以批判性的耳朵聆聽。在重播時,專注於具體細節:人聲是否清晰地浮現在樂器之上?鼓點是否保持穩定的節奏?是否有任何段落顯得格格不入或過於重複?寫下兩到三個觀察結果。
這就是完整的循環。從輸入提示詞到聽到完成的歌曲,整個過程耗時不到五分鐘。速度是其價值的一部分——您可以快速迭代,而不是花費數小時在單一版本上。
如何以未經訓練的耳朵評估 AI 輸出品質
這裡有一個大多數指南完全忽略的挑戰:您是初學者,這意味著您的耳朵未經訓練,無法捕捉製作人能立即發現的問題。當您尚不知道技術上「好」的聲音聽起來是什麼樣子時,如何評估 AI 音樂輸出的品質?
答案比您想像的簡單。您不需要專業的耳朵就能捕捉 AI 生成音樂中最常見的問題。您只需要知道要聽什麼。iZotope 的聽力訓練研究強調,即使對於初學者而言,針對特定目標進行專注聆聽也比被動聽覺更有效。在此應用該原則,檢查每次生成的以下四個品質:
- 清晰度 — 您能否清晰地聽到每個元素?人聲不應被樂器淹沒。吉他、貝斯和鼓等個別部分應佔據各自的空間。如果所有聲音混合成一堵模糊的聲音牆,則混音存在清晰度問題。
- 渾濁感 — 低頻聽起來是否腫脹或轟鳴?當太多能量堆積在 200-500 Hz 範圍時,就會出現渾濁感。如果曲目感覺「沉重」且令人不適而非刻意為之,那就是渾濁感。將其與同類型的專業發行歌曲進行比較,注意參考曲目中的低頻是否更緊緻。
- 削波和失真 — 聆聽較大聲時刻(特別是鼓擊和人聲峰值)是否有刺耳的爆裂聲或破碎聲。這是由於音頻超過其最大電平而導致的數位失真。聽起來就像疊加在聲音上的靜電噪音。如果您聽到這種情況,表示生成過程存在技術問題,您應該重新生成。
- 節奏一致性 — 鼓點是否在整個過程中保持穩定的節奏,或者您是否注意到時機絆倒或感覺不自然的時刻?AI 生成的音樂偶爾會產生微小時機錯誤,聽起來像是一個略微喝醉的鼓手。隨著節拍跺腳。如果您的腳在任何時刻想要猶豫或結巴,則節奏存在問題。
一個實用的技巧:在您喜歡的同類型參考歌曲之後立即播放您生成的曲目。對比使問題顯而易見。當兩首曲目連續播放時,您的耳朵自然會注意到飽滿度、清晰度和能量的差異。您不需要多年的訓練就能聽出其中一首聽起來專業,而另一首聽起來單薄或渾濁——您只需要直接比較即可。
還有一件初學者經常忽略的事情需要注意:段落之間的過渡。主歌是否自然流暢地進入副歌,還是感覺像是兩段獨立的內容生硬拼接在一起?AI 模型有時難以處理平滑的段落過渡,導致能量突然變化或出現尷尬的靜默。如果某個過渡讓你從音樂中抽離出來,請將其標記為需要解決的問題。
何時重新生成 versus 何時進行優化
你已經進行了批判性聆聽。你有了筆記。這首曲目並不完美。問題是:你是應該將其丟棄並重新開始,還是保留有效的部分並修復無效的部分?
這個決策點是初學者浪費最多時間和積分的地方。以下是一個清晰的框架:
在以下情況下從頭重新生成:
- 流派或整體氛圍根本錯誤 — 你要求的是低保真嘻哈(lo-fi hip-hop),得到的卻是電子舞曲(EDM)。
- 人聲風格與你的願景完全不符 — 性別錯誤、能量錯誤、語言錯誤。
- 歌曲結構混亂 — 各段落之間沒有邏輯地相互混雜,或者編排在音樂上毫無意義。
- 存在技術瑕疵,如整個曲目中存在嚴重的削波、極度失真或音頻故障。
在以下情況下優化提示詞並重新生成:
- 流派和情緒正確,但節奏感覺太快或太慢 — 將 BPM 調整 10-15。
- 樂器配置接近但有一個元素錯誤 — 在提示詞中將「電吉他」替換為「原聲吉他」。
- 能量水平略有偏差 — 添加描述詞如「簡約」(stripped-back)或「強勁」(driving)以將其推向正確方向。
- 人聲不錯但歌詞感覺平庸 — 貼上你自己的歌詞,而不是依賴 AI 生成的文本。
一般規則:如果你喜歡 AI 生成內容的 50% 以上,請進行優化而不是重新生成。根據你的批判性聆聽筆記,修改提示詞中的一兩個元素,然後再次生成。正如AI 音樂工具的實用指南中所述,經驗豐富的用戶形成的模式是保留他們喜歡的版本,並對錯誤的部分進行精細修復,而不是賭一把重新生成並失去原本有效的部分。
如果你喜歡的程度低於 50%,則說明你的提示詞在某些根本方面與你的意圖不符。回到第 3 步中的提示詞結構,重新考慮你的流派和情緒錨點,並嘗試一個有意義的不同描述,而不是微調同一個失敗的描述。
你的第一首可發布曲目可能需要三到五次生成。這很正常。每次生成都會教你一些關於工具如何解釋你的文字的知识,這些知識會隨著你製作的每首曲目而累積。
此時,你已經擁有了一首令你真正滿意的曲目。它聽起來完整,混音清晰,能量符合你的願景。但原始的 AI 導出文件很少是最終產品。一首聽起來「相當不錯」的曲目與一首聽起來專業的曲目之間的區別,往往取決於生成之後的操作:編輯、混音以及針對目標平台使用正確的設置進行導出。
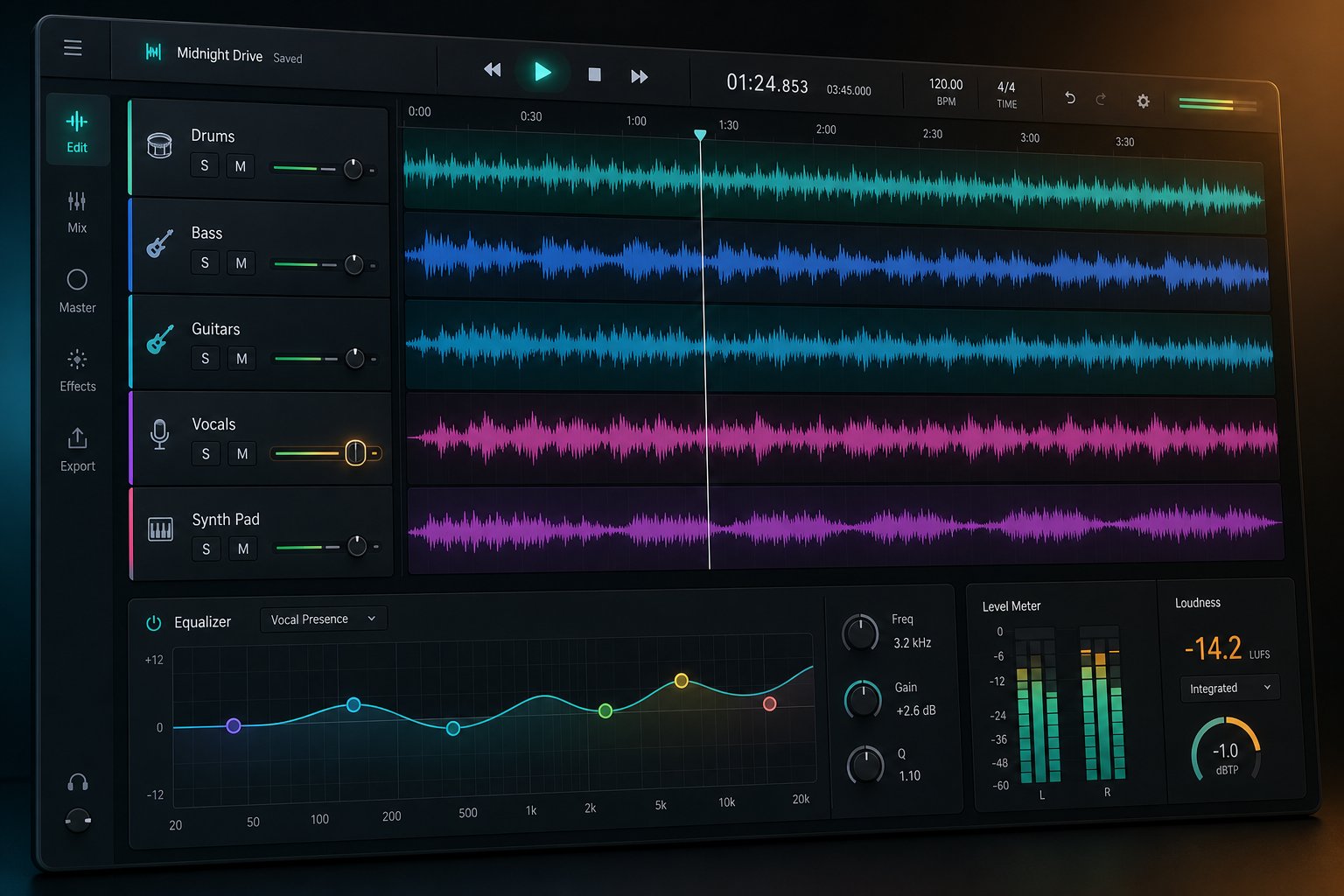
步驟 5:正確編輯、混音和導出你的 AI 音樂
單一 AI 工具可以生成完整的曲目,但專業級的結果往往來自結合多個工具的輸出並應用基本的人工編輯決策。將 AI 輸出視為原材料 — 一個堅實的基礎,在到達聽眾之前受益於修剪、分層、平衡和格式化。這就是了解如何混音和編輯 AI 生成音樂將隨意實驗與你真正自豪發布的曲目區分開來的地方。
好消息是:你不需要多年的音頻工程經驗就能做出有意義的改進。即使是簡單的編輯,如移除開頭的靜默、調整音量水平和以正確格式導出,也會產生明顯的差异。讓我們分解完整的生成後工作流程。
在一個項目中結合多個 AI 工具
大多數初學者堅持使用一個平台完成所有工作,但真正的創意優勢來自於了解如何在一個項目中結合多個 AI 音樂工具。每類工具擅長不同的任務,在它們之間路由輸出會產生單一工具無法單獨實現的結果。
以下是初學者可以遵循的實用多工具工作流程:
- 生成你的器樂基礎,使用文字轉歌曲生成器。將結果匯出為 WAV 檔案(如果平台提供,可使用音軌分離功能),以獲取鼓、貝斯、旋律和鋪墊音效的獨立音軌。
- 單獨生成人聲,如果你希望對演唱風格、樂句處理或語言有更多的控制權,而非僅依賴主要生成器提供的選項,請使用專用的 AI 人聲工具。將人聲匯出為獨立的 WAV 檔案。
- 將所有元素匯入免費的數位音訊工作站 (DAW) 或編輯器,例如 Audacity、GarageBand(macOS)或 Cakewalk(Windows)。將每個檔案放置在各自的音軌上,以便你可以獨立控制音量、時間和位置。
- 修剪、編排和分層。 剪掉開頭和結尾的無聲部分。如果時間出現偏差,請將人聲與器樂對齊。添加淡入或淡出效果,使開頭和結尾更加平滑。
- 進行基本修飾,使用均衡器 (EQ) 和音量調整(下文將介紹),然後以目標平台要求的格式匯出最終混音。
這種模組化方法反映了專業製作人的工作方式,只是由 AI 處理生成步驟,取代了現場錄音會議。隨著近期 2026 年 AI 音樂工具更新,如 Suno 的音軌提取功能和 Soundverse 的編曲工作室,即使在入門級方案中,從 AI 生成器中提取單獨元素也變得簡單易懂。
一個關鍵原則:將每個 AI 輸出視為一種食材,而不是成品佳餚。來自一個工具的節拍、另一個工具的旋律以及第三個工具的人聲,可以組合成比任何單一生成結果更連貫且獨特的作品。
AI 音軌的基本混音和編曲
混音聽起來可能令人畏懼,但在初學者階段,它歸結為三個控制項:音量、聲像定位和均衡器 (EQ)。掌握這三者,你的 AI 音軌會立即聽起來更加精緻且有意圖感。
- 音量平衡 — 這是你能做出的最具影響力的調整。如果人聲被響亮的器樂掩蓋,將器樂音量降低 3 到 6 dB 即可立即解決問題。目標是讓每個元素都清晰可聞,沒有任何單一部分不自然地佔據主導地位。首先將人聲或主旋律設定為最大音量,然後將輔助元素調整至較低音量。
- 聲像定位 (Panning) — 聲像定位將聲音在立體聲場中向左或向右移動。如果所有元素都集中在正中央,混音會顯得狹窄且擁擠。嘗試將節奏吉他稍微向左和向右平移(各約 30%),保持貝斯和人聲居中,並將鋪墊音效或氛圍元素擴展得更寬。這樣可以在不需要高級技巧的情況下創造空間感和深度。
- 均衡器 (EQ) — EQ 允許你提升或削減特定頻率範圍。對於初學者來說,最有用的操作是對除貝斯和底鼓以外的所有內容應用高通濾波器。將其設定在 80 到 100 Hz 左右,它可以去除導致渾濁的低頻轟鳴聲。如果人聲聽起來悶悶的,嘗試在 3 到 5 kHz 附近輕輕提升,以增加存在感和清晰度。這裡不需要手術般的精準度——廣泛且簡單的調整就能帶來實質差異。
一個能顯著改善 AI 音軌的編曲決策:不要讓每種樂器從頭到尾持續演奏。AI 生成器傾向於產生密集的編曲,所有樂器同時演奏。在主歌開頭靜音鼓組,在副歌到來前去掉貝斯,或者只保留人聲和鋼琴四個小節,這些都能創造吸引聽眾注意力的動態對比。你可以在任何編輯器中通過簡單地剪切或靜音個別音軌的部分來實現這一點。
不同平台的匯出設定
你已經完成了音軌混音,聽起來平衡且清晰,準備好分享它。此時,了解 AI 音樂串流平台的最佳匯出設定,可以防止你的作品被發行商拒絕,或在播放時音质不如預期。
每個平台都有特定的技術要求。上傳不符合這些要求的檔案,你會收到錯誤訊息,或者你的音訊會被自動重新編碼——其質量往往低於你最初正確匯出的質量。
| 平台 | 格式 | 取樣率 | 位元深度 | 位元率(如有損) | 備註 |
|---|---|---|---|---|---|
| Spotify(透過發行商) | WAV 或 FLAC | 44.1 kHz | 16-bit 或 24-bit | 不適用(無損上傳) | Spotify 會在內部轉碼為 OGG Vorbis;請上傳最高質量的源檔案 |
| Apple Music(透過發行商) | WAV 或 AIFF | 44.1 kHz 或更高 | 首選 24-bit | 不適用 | 支援空間音訊;24-bit 標準立體聲為理想選擇 |
| YouTube | WAV 或 FLAC | 48 kHz | 16-bit 或 24-bit | 不適用 | 48 kHz 符合 YouTube 的視頻標準;避免取樣率轉換 |
| Instagram / TikTok | MP3 或 AAC | 44.1 kHz | 不適用 | 256-320 kbps | 平台壓縮力度大;320 kbps MP3 可在重新編碼過程中保留質量 |
| SoundCloud | WAV 或 FLAC | 44.1 kHz | 16-bit 或 24-bit | 不適用 | SoundCloud 為免費聽眾轉碼為 128 kbps;無損上傳可提供最佳源檔案 |
| 播客託管 | MP3 | 44.1 kHz | 不適用 | 128-192 kbps | 單聲道 128 kbps 是語音內容的標準;立體聲音樂片頭使用 192 kbps |
通用規則:始終先將你的母帶檔案匯出為無損格式(44.1 kHz、24-bit 的 WAV)。將其作為存檔副本保留。然後根據需要從該母帶創建特定平台的版本。將 MP3 轉換回 WAV 無法恢復丟失的質量,因此從無損格式開始可以保護你免受不可逆的質量降級。
如果您是透過 DistroKid、TuneCore 或 Amuse 等發行商將音樂上傳至串流服務,他們通常要求最低為 44.1 kHz 的 WAV 或 FLAC 格式。部分平台接受 48 kHz 或更高規格,但 16 位元深度的 44.1 kHz 是安全且通用的標準,所有發行商和平台都能無縫接受,不會出現轉換問題。
對於注重檔案大小的社群媒體貼文,請另行匯出 bitrate 為 320 kbps 的 MP3 檔案。在手機揚聲器和耳機上,320 kbps MP3 與無損 WAV 之間的音質差異幾乎聽不出來,而檔案大小則會減少約 80%。請使用您的無損母帶進行專業發行,並使用 MP3 進行快速分享。
關於響度,有一點值得注意:串流平台會將音量標準化至目標水準(Spotify 使用 -14 LUFS,YouTube 使用 -13 至 -15 LUFS)。如果您的曲目明顯高於或低於該目標,平台會自動調整播放音量。對於初學者來說,這意味著您無需為了在響度上競爭而使用重度限制器壓抑混音。請以自然、具動態範圍的水準匯出,讓平台處理標準化。過度响亮且缺乏動態範圍的母帶在標準化後聽起來反而更差,而非更好。
當您擁有適當混音並正確匯出的曲目時,您就準備好與世界分享作品了。但在上傳到任何地方之前,有一個關鍵問題需要解答:您實際上被允許如何使用這首音樂?AI 生成音訊的法律環境與大多數創作者以往所遇到的情況截然不同,誤解它可能導致曲目被下架、收入損失,甚至更嚴重的後果。
步驟 6:在發佈前了解版權與授權
您的硬碟中存放著一首經過精修並正確匯出的曲目。直覺告訴您要立即將其上傳到所有平台。但這裡有一個讓幾乎每位 AI 音樂初學者都陷入困境的問題:您可以合法銷售 AI 生成的音樂嗎?簡短的回答是肯定的,但更詳細的答案涉及理解版權所有權與商業授權之間的區別,因為在 AI 音樂領域,這兩者並不相同。
傳統音樂擁有明確的所有權模式。您創作一首歌曲,便自動擁有版權,並控制其使用方式。AI 生成的音樂以法律體系仍在釐清的方式打破了這種模式。現在掌握基本知識可以保護您,避免發佈無法變現的作品,或者更糟的是,在曲目已經獲得關注後被平台下架。
誰擁有 AI 生成音樂的版權以及您擁有的權利
針對初學者的 AI 音樂版權與所有權規則歸結為一個基本原則:大多數司法管轄區要求有人類作者身分才能獲得版權保護。純 AI 輸出(即您輸入提示詞,模型在沒有實質性人類創意輸入的情況下生成所有内容)通常不符合在美國、歐盟或大多數其他主要市場進行版權登記的資格。
美國版權局目前的立場將 AI 音樂分為三類:
- 純 AI 生成 — 不可受版權保護。無法識別人類作者,該作品實際上可能進入公共領域。
- AI 輔助創作 — 如果您能證明存在實質性的人類創意,則可能受版權保護。撰寫原創歌詞、進行廣泛編輯、編排段落以及做出 deliberate 的製作選擇,都能加強您的主張。
- 人類與 AI 協作 — 當存在明確的人類作者身分且 AI 作為工具而非作者時,很可能受版權保護。適用傳統版權法。
這在實際操作中意味著什麼?如果您生成一首曲目後未進行任何修改,您可能無法為其註冊版權。但如果您撰寫原創歌詞、重新編排結構、在數位音訊工作站(DAW)中混音、疊加自己的錄音素材,或在整個過程中做出重大創意決策,您的貢獻可能會受到保護。您加入的人類創意越多,您的立場就越穩固。
以下是大多數初學者忽略的關鍵細微差別:版權與商業權利是分開的概念。您無需擁有版權即可銷售、發行或變現 AI 音樂。您商業使用曲目的能力來自於您的 AI 工具的許可協議,而非版權法。這一區別至關重要。
您必須了解的平台服務條款
每個 AI 音樂工具根據您的訂閱等級授予不同的權利。您可以對生成的曲目進行的合法操作完全取決於您在創建它們時訂閱的方案。免費層級幾乎普遍限制商業用途,而付費方案則授予商業授權權利。
平台之間的差異十分顯著:
- Suno Free — 僅供個人使用。您不得分發、變現或出售在免費層級創建的曲目,即使您日後升級亦然。必須註明 Suno 出處。
- Suno Pro(每月 $10) — 授予完整商業權利。無需註明出處。您可以分發至串流平台、直接銷售以及在影片中變現。
- AIVA Free/Standard — AIVA 保留版權所有權。變現權利有限或完全沒有。必須註明出處。
- AIVA Pro(每月 49 歐元) — 聲稱將實際版權所有權轉移給您,這使其在 AI 音樂工具中獨樹一幟。
所有平台均適用一項規則:在免費層級創建的歌曲無法透過日後升級來追溯進行商業化。如果您計劃將曲目變現,請在有效訂閱付費計劃期間創建它。在有效付費訂閱期間創建的歌曲將永久保留其商業權利,即使您隨後取消訂閱亦然。
除了您的 AI 工具條款外,串流平台和分銷商還增加了另一層限制。LANDR 和 DistroKid 等分銷商要求您認證您擁有上傳每首曲目的分發權利。您付費的 AI 工具訂閱即作為該認證。部分分銷商還對完全由 AI 生成的發行作品設定限制以防止垃圾內容,而 Spotify 和 Deezer 等平台開始單獨標記 AI 生成的內容。
YouTube Content ID、TikTok 和 Meta 等變現渠道要求嚴格的原創性標準。即使允許更廣泛的串流分發,您的分銷商也可能限制 AI 生成的音樂進入這些特定渠道。在假設曲目可以無處不在之前,請務必驗證您的分銷商針對 AI 的具體政策。
將您的 AI 音樂變現的安全方法
了解如何在串流平台上將 AI 生成的音樂變現,始於知道哪些用例在當前許可結構下是明確允許的。以下是最常見的變現途徑及其典型要求:
- 在 Spotify、Apple Music 和 YouTube Music 上串流 — 需要付費的 AI 工具訂閱(商業權利)和分發服務。無需版權註冊。您從 AI 工具獲得的許可已足夠。
- YouTube 背景音樂 — 憑藉您 AI 工具的商業權利允許。透過您自己影片上的廣告進行變現。除非您的分銷商在其指紋識別系統中明確支持 AI 內容,否則避免進行 Content ID 註冊。
- 播客開場和背景配樂 — 大多數付費 AI 工具計劃涵蓋的直接商業用途。為您自己的播客使用無需額外許可。
- 直接銷售節拍或曲目 — 憑藉商業權利允許。在 Bandcamp、Gumroad 或您自己的網站上銷售。如果平台或您的市場要求,請披露 AI 生成情況。
- 電影、廣告和影片的同步許可 — 較為複雜。大多數付費 AI 工具計劃包括同步權利,但一些庫和製作公司可能需要您無法為純 AI 輸出提供的版權文件。在此情況下,添加大量的人類創意會加強您的立場。
也有一些您不應跨越的明確界限。不要聲稱虛假的人類作者身份。不要將免費層級的輸出演用於商業目的。不要以構成冒充的方式複製可識別的藝術家聲音或風格。並且不要在未添加有意義的人類創意貢獻時假設存在版權保護。
在商業使用任何 AI 工具之前,請務必閱讀其具體的服務條款。條款因平台而異,隨時間變化,並根據您的訂閱層級而有所不同。您的權利由合約定義,而非假設。
文件記錄比大多數初學者意識到的更為重要。保留您的訂閱日期、哪些曲目是在哪個層級創建的、付款收據以及您對 AI 進行的任何人為修改的記錄。如果分銷商或平台質疑您的權利,這些書面記錄就是您的證明。保存您的提示詞、迭代歷史和編輯決策,作為您創作過程的證據。
圍繞 AI 音樂的法律格局正在積極演變,多個司法管轄區正在開發新框架,法院案件也在確立先例。隨著更清晰的法規出現,今天可行的做法可能會發生變化。最安全的長期策略是將 AI 用作創意工具而非完全自主的創作者,為您計劃變現的每首曲目添加真正的人類貢獻,並在政策更新時保持知情。
隨著法律基礎清晰,拼圖的最後一塊是將您的音樂從電腦上的完成文件轉移到串流平台上的即時曲目,讓聽眾可以找到它。分發是一個獨立的過程,具有特定的要求、時間表和成本,這是大多數初學者指南從未涵蓋的。

步驟 7:發行您的 AI 音樂並建立學習常規
您的曲目已混音完成、正確匯出,並已取得商業使用的法律許可。它作為一個 WAV 檔案存在於您的硬碟中。該檔案與在 Spotify、Apple Music 或 YouTube Music 上線的歌曲之間的差距比大多數人預期的要小,但這涉及具體的步驟,無論創意才華多高都無法跳過。了解如何在 Spotify 上發行 AI 生成的音樂,需要理解元數據、封面藝術規格、發行服務以及實際的時間表。讓我們逐步介紹整個流程。
將您的曲目從匯出到串流平台
串流平台不接受獨立藝術家的直接上傳。您無法將 WAV 檔案拖曳到 Spotify 並點擊發佈。相反,每個獨立發行作品都必須通過數位發行服務,該服務充当您與全球 150 多個串流平台之間的中間人。發行商代表您處理交付、元數據格式化、版稅收集和平台合規性。
在上傳至任何發行商之前,您需要準備好以下三項內容:
- 音訊檔案 — WAV 或 FLAC 格式,採樣率為 44.1 kHz,位元深度至少 16-bit(建議 24-bit)。這是您在步驟 5 中匯出的無損母帶。大多數發行商拒絕接受 MP3 上傳。
- 封面藝術 — 一張 3000x3000 像素的正方形圖片,格式為 JPG 或 PNG。不要使用模糊的照片,文字大小在縮略圖尺寸下必須清晰可讀,且不得包含受版權保護的圖像。這是聽眾在各個平台上看到的內容,因此其重要性超出初學者的預期。
- 完整的元數據 — 歌曲標題、藝術家名稱、類型標籤、發行日期、詞曲作者署名和語言。ISRC 代碼(國際標準錄音代碼)用於識別每首單獨的曲目,而 UPC 代碼則用於識別整個發行作品。許多發行商會在上傳過程中自動生成這些代碼,因此您無需單獨購買。
時間表的預期在這裡很重要。從上傳到正式發行的典型窗口期為 3 到 4 週。這包括 1 到 7 天的發行商處理和審核時間,然後是 Spotify 和 Apple Music 等平台使您的曲目上線所需的額外 2 到 5 天。設置額外的提前量是因為歌單投稿(這可以顯著提升您首週的數據)需要在發行日期之前進行。匆忙趕工會完全錯失這個機會。
一個實用的建議:選擇星期五作為發行日期。平台演算法和編輯團隊會將注意力集中在星期五發行的作品上,而且大多數主要唱片公司的新歌也在這一天發佈。與這一節奏保持一致,可以讓您的曲目最有機會出現在演算法推薦中,與新鮮內容並列展示。
發行服務及其費用
針對初學者的 AI 音樂發行逐步流程始於選擇合適的服務。發行商在定價模式、版稅分成、交付速度和包含的功能方面各不相同。對於發佈第一首 AI 生成曲目的人來說,決策取決於您計劃發行的頻率以及您願意預付多少費用。
以下是基於2026 年當前定價的主要選項:
- DistroKid — 每年起價 $22.99,可無限上傳。不抽取串流版稅(0%)。審核後約 2 到 5 天內交付至 Spotify。最適合每月發佈多首曲目的多產創作者。部分功能(如 YouTube Content ID)收取 20% 的佣金。
- TuneCore — 每位藝術家每年 $14.99,可無限上傳。標準計劃不抽取版稅(0%)。批准後 2 到 5 個工作日內交付至 Spotify。免費包含曲目拆分和 Spotify Discovery Mode 功能。
- CD Baby — 每首單曲一次性付款 $9.99(無需每年續費)。抽取串流收入的 9%。交付時間從 2 到 4 週不等。更適合發行頻率較低且偏好按項目付費的藝術家。
- Amuse — 每位藝術家每年起價 $23.99。不抽取版稅(0%)。交付時間較慢,客戶支援較為有限,但適合以最小投資試水的初學者。
對於您的首次發行,DistroKid 或 TuneCore 提供了低成本、快速交付和零串流佣金的最佳平衡。如果您計劃總共只發行一兩首曲目,CD Baby 的一次性費用可以避免持續的成本。所有這些服務預設都會在全球範圍內發行,將您的曲目同時上架到 Spotify、Apple Music、Amazon Music、YouTube Music、TikTok、Deezer 以及數十個區域平台。
上傳後,請在您的曲目上線後盡快认领您的 Spotify for Artists 個人資料。這將解鎖顯示聽眾人口統計資料、儲存率和播放清單收錄情況的分析數據。驗證需要 1 至 3 個工作天,並讓您能夠控制藝術家頁面的外觀、簡介以及即將發行的推廣活動。
對收入的預期應切合實際。獨立藝術家通常在 Spotify 每次串流播放中賺取約 $0.004,這意味著大約 250,000 次串流播放可產生約 $1,000 的收入。您的第一首曲目不會立即達到這些數字,這沒關係。首次發行的目標是完成整個流程、學習過程,並擁有一首可以推薦給他人的上線曲目。
您的 7 天初學者課程:從零到出版
本指南中的所有內容,從工作區設置到發行,如果視為一個整體可能會讓人感到不知所措。將其分解為結構化的 7 天 AI 音樂製作初學者學習計劃,可使這段旅程變得易於管理。每天都有特定的目標和明確的交付成果,因此您永遠不必疑惑下一步該做什麼。
- 第 1 天:設置您的工作區。安裝 Audacity 和現代瀏覽器。測試您的網際網路速度。將您想嘗試的兩三個 AI 音樂工具加入書籤。在每個工具上創建免費帳戶。交付成果:一個已創建所有帳戶、隨時可用的工作區。
- 第 2 天:學習提示基礎知識。閱讀步驟 3 中的提示工程原則。使用「情緒 + 類型 + 樂器編制 + tempo」公式編寫五個不同的提示。使用免費層級從每個提示生成一首曲目。暫時不要評判質量——只需觀察不同提示如何產生不同的輸出結果。交付成果:五首生成的曲目以及關於每個提示所產生結果的筆記。
- 第 3 天:優化與迭代。挑選第 2 天中最好的生成結果。使用四點評估框架(清晰度、混濁度、削波、節奏)進行批判性聆聽。根據您想要改變的地方重寫您的提示。生成三個優化版本。進行比較。交付成果:一首您在音樂上滿意的曲目。
- 第 4 天:編輯與混音。將您最好的曲目匯入 Audacity。修剪開頭和結尾的靜音部分。標準化音量。對最後四秒應用淡出效果。如果您有分軌檔案,請練習元素之間的基本音量平衡。以 44.1 kHz、24-bit 导出為 WAV 格式。交付成果:一個經過打磨且正確導出的音頻檔案。
- 第 5 天:準備發行素材。創建或委託製作您的 3000x3000 像素封面藝術作品(Canva 適用於簡單設計)。編寫您的歌曲標題、藝術家名稱和類型標籤。決定至少三週後的發行日期。研究哪種發行商適合您的預算。交付成果:所有元數據和藝術作品已準備好上傳。
- 第 6 天:上傳與排程。註冊您選擇的發行商。上傳您的 WAV 檔案,附加您的藝術作品,填寫所有元數據欄位,並設置您的發行日期。選擇全球發行。檢查您的藝術家名稱和歌曲標題是否有拼寫錯誤——這些在交付後很難更正。交付成果:由發行商確認的已排程發行。
- 第 7 天:規劃您的推廣和下一步。使用您曲目中 15 秒的精彩片段創建一個短的 TikTok 或 Instagram 剪輯。起草一篇宣佈您即將發行的貼文。設置日曆提醒,以便在曲線上線後认领您的 Spotify for Artists 個人資料。開始為您的第二首曲目編寫提示。交付成果:準備好在發行日發布的推廣內容,以及第二首曲目的提示草稿。
在這七天的歷程結束時,您將從零知識轉變為一首已排程在全球串流平台上發行的曲目。這就是完整的「從第一天到完成」之旅。此後的每一步都是迭代:更好的提示、更精細的混音、更聰明的推廣,以及不斷增長的已出版作品目錄。
那些建立真正勢頭的製作人將這第一首曲目視為概念證明,而非最終成就。您現在了解了整個流程。第二首曲目所需的時間減半,因為您不再是在學習工具——而是在使用它們。第三首則需要更少的時間。在一個月的一致練習後,生成、編輯和發行曲目將成為一個可重複的過程,而不是一個令人不知所措的项目。
今天就開始。打開您的 AI 工具,輸入您的第一個提示,讓課程帶領您一天天地前進。