
Can AI Music Be Detected or Are We Already Fooled
Imagine hearing a track that gives you chills. The melody hooks you, the vocals feel raw and emotional, and you add it to your playlist without a second thought. But what if that song was never touched by human hands? Can AI music be detected, or has the technology already crossed a line where our ears simply cannot keep up?
The answer is not a clean yes or no. Detection exists on a spectrum, where confidence levels shift depending on the method used, the AI generator behind the track, and how much post-processing has been applied. Some approaches catch AI-generated audio with reasonable accuracy. Others fail completely against the latest models.
In a blind listening test commissioned by Deezer and conducted by Ipsos across 9,000 participants in eight countries, 97% of respondents could not distinguish fully AI-generated music from human-made tracks.
That Deezer-Ipsos survey is not a fringe finding. It reflects a reality that casual listening, the way most of us consume music, is no longer a reliable ai music detector. More than half of those surveyed felt uncomfortable knowing they could not tell the difference. The question "is this song ai" is no longer hypothetical. It is something listeners, creators, and platforms face daily.
The Detection Challenge in Plain Terms
AI music generation has crossed a quality threshold that makes it functionally invisible to untrained ears. Tools like Suno and Udio produce full songs in seconds, complete with vocals, instrumentation, and polished production. BBC reporting highlights that an entire song can now be summoned rapidly with a single prompt, a far cry from the early days when generating one minute of audio took roughly ten hours.
This speed and quality mean streaming platforms are flooded with synthetic content. Deezer alone receives over 50,000 fully AI-generated tracks every day, accounting for 34% of all daily uploads. When you are scrolling through a playlist, the odds of encountering AI content without realizing it are higher than most people assume. Traditional ai music detectors are racing to keep pace, but the generators keep improving.
So how to tell if music is ai generated? That depends on who you are and what tools you have access to. A casual listener relying on gut feeling will miss almost everything. An ai detector music tool scanning spectral patterns will catch more, but not all. The most reliable results come from layering multiple detection approaches together.
Who Needs to Know and Why
This article serves three distinct audiences, each with different stakes in the detection question:
- General listeners who want to know whether the music they love and support financially is made by real artists or generated by algorithms.
- Music creators and submitters who need to prove their work is human-made when submitting to platforms, labels, and curators, or who want to use an ai song detector to vet collaborators.
- Platform operators and curators who must enforce content policies, protect royalty pools, and maintain trust with their user base.
Each group faces a different version of the same problem. For listeners, it is about informed choice. For creators, it is about livelihood and credibility. For platforms, it is about scale and policy enforcement. The detection methods that work for one group may not suit another, which is why a layered understanding matters more than any single tool or trick.
The real consequences of getting detection wrong, from lost royalties to platform removal, extend far beyond curiosity.
Why AI Music Detection Matters for Every Creator
Detection is not just a technical puzzle for researchers to solve in a lab. It carries real financial weight. When a platform flags your track as AI-generated, the consequences hit fast: lost revenue, rejected submissions, and in some cases, permanent removal from the services where your audience lives. For independent ai music artists trying to build sustainable careers, the stakes could not be higher.
The music industry generated over $10 billion in payouts on Spotify alone in 2024, up from $1 billion in 2014. That growth attracts bad actors. Content farms using AI generators flood platforms with synthetic tracks designed to siphon royalties from the shared pool. Every stream directed toward a spam track is a fraction of a cent pulled away from a human artist who spent months writing, recording, and mixing their work. Detection is the mechanism that protects that pool.
Platform Policies and Submission Rejections
Streaming services and submission platforms are drawing harder lines around AI content. Does Spotify allow AI music? The short answer: yes, but with significant guardrails. Spotify's updated policies target impersonation, mass-generated spam, and undisclosed AI usage. Their new music spam filter identifies uploaders engaging in tactics like mass uploads, duplicates, and artificially short tracks, then stops recommending them. In the past 12 months, Spotify removed over 75 million spammy tracks from the platform.
The transparency push goes deeper. Spotify is helping develop an industry-standard AI disclosure system through DDEX, the metadata framework used across streaming services. This Spotify AI DDEX integration allows artists and distributors to indicate exactly where AI played a role in a track, whether in vocals, instrumentation, or post-production. The goal is nuanced labeling rather than a binary "AI or not AI" stamp. As of early 2026, a beta feature lets artists share how they used AI directly in Song Credits on mobile.
DistroKid, one of the largest independent distributors, accepts AI-assisted music but enforces strict rules: you must own 100% of the rights, your music cannot impersonate another artist, and mass-generated spam violates their policies. Releases that fail to meet streaming service guidelines face rejection or removal after the fact.
On the curation side, platforms like SubmitHub process tens of millions of submissions from artists seeking playlist placements and blog coverage. Any submithub review now carries the implicit question of whether the track is genuinely human-made. Curators who accept AI-generated content risk their own credibility, so detection has become part of their gatekeeping process. A false positive, where a human track gets flagged as AI, can mean a missed opportunity that never comes back.
Financial and Legal Consequences
The economic fallout from detection outcomes extends well beyond a single rejected submission. When platforms identify AI-generated content that was uploaded without proper disclosure, the consequences cascade quickly.
- Platform removal — Tracks pulled from streaming services lose all accumulated streams, playlist placements, and algorithmic momentum permanently.
- Royalty clawback — Platforms can reclaim royalties already paid on content that violated their terms, leaving artists with negative balances.
- Submission rejection — Curators, playlist editors, and blogs increasingly reject tracks that trigger AI detection flags, closing promotional pathways.
- Reputational damage — Being publicly identified as submitting undisclosed AI content erodes trust with fans, collaborators, and industry contacts.
- Legal liability — Copyright disputes over AI-generated material can result in damages up to $150,000 per infringed track, according to RIAA filings against AI music companies.
The legal landscape is shifting rapidly. In the US, the Copyright Office confirmed that 100% AI-generated content cannot be copyrighted and falls into the public domain. That means if you generate a track entirely with AI and someone else copies it, you have no legal recourse. Meanwhile, major labels have launched coordinated lawsuits against AI generators like Suno and Udio, with potential damages reaching billions. The UK government scrapped plans to allow AI training on copyrighted music without permission after overwhelming industry backlash, with 95% of consultation respondents opposing the opt-out approach.
For independent musicians, this creates a double bind. Music industry AI news is dominated by stories of labels suing AI companies, but the downstream effects hit smaller artists hardest. If you are submitting demos to music labels accepting demos or pitching to record companies accepting demos, any association with undisclosed AI content can disqualify your submission before anyone listens to the music itself. Labels want to invest in artists who own clear, defensible copyrights, not tracks built on legally uncertain foundations.
The financial reality is stark. Deezer reports receiving over 30,000 fully AI-generated tracks daily. Spotify's royalty pool is finite. Every synthetic track that slips through detection dilutes payouts for legitimate artists. Detection is not just about identifying fakes. It is the infrastructure that keeps the economics of music creation viable for humans who depend on it.
Understanding the consequences clarifies why detection methods matter so much. The question shifts from whether AI music can be identified to how the identification actually works at a technical level.
How Technical Detection Methods Actually Work
Knowing the consequences is one thing. Understanding how detection actually happens under the hood is another. When an ai song analyzer scans a track, what is it actually looking for? The answer involves multiple layers of analysis happening simultaneously, each targeting a different weakness in how AI generators produce audio.
Think of it this way: every recording carries invisible fingerprints. A human performance captured through microphones, mixed on a console, and mastered through analog hardware leaves a specific pattern in the audio data. AI generators, no matter how sophisticated, leave a different pattern. The trick is knowing where to look.
AI music analysis relies on the fact that neural audio generators use mathematical processes (specifically deconvolution layers) that produce systematic artifacts in the frequency domain. These artifacts are architecture-dependent, meaning they exist regardless of what the AI was trained on or what style of music it produces. A simple logistic regression model with just 10,000 parameters achieved over 99% accuracy detecting these artifacts in both open-source and commercial generators, according to research presented at ISMIR 2025.
Spectral Analysis and Frequency Fingerprints
Spectral analysis examines how energy is distributed across frequencies in an audio file. When you look at a spectrogram of a human recording versus an AI-generated track, the differences are invisible to your ears but measurable by algorithms.
AI generators like Suno and Udio leave behind what researchers describe as a "metallic high-frequency shimmer" — systematic spectral peaks at predictable frequency intervals. These peaks are a byproduct of the neural network architecture itself, not the musical content. You could generate a jazz ballad or a death metal track, and the same spectral fingerprint would appear in both.
Detection systems also examine Mel-Frequency Cepstral Coefficients (MFCCs), which represent the spectral envelope of sound in a way that correlates with how humans perceive timbre and pitch. AI-generated audio typically shows different MFCC distributions than human recordings, particularly in the higher coefficients that capture fine spectral detail. Song analysis ai tools process these coefficients alongside Linear Frequency Cepstral Coefficients and Constant-Q Cepstral Coefficients through separate neural network streams to build a comprehensive spectral profile.
Research from the ISMIR study on AI music detection found that Suno tracks have a lower average spectral centroid than both Udio and human recordings from the Million Song Dataset, suggesting reduced high-frequency content. Suno also shows higher bark bands kurtosis, indicating more extreme spectral peaks and sharper transient sounds. These measurable differences give music analysis ai systems concrete data points to work with.
Pattern Recognition and Machine Learning Classifiers
Spectral analysis provides the raw data. Pattern recognition is what turns that data into a detection verdict.
One of the most effective approaches uses Contrastive Language-Audio Pretraining (CLAP) embeddings. CLAP is a model that learns to represent audio in a compact mathematical space by connecting audio concepts with natural language descriptions. It processes audio into a 512-dimensional vector that captures the essential characteristics of a recording. When you feed thousands of AI-generated and human-made tracks through CLAP, the resulting embeddings cluster differently in that mathematical space.
Researchers at KTH Royal Institute of Technology built detection systems using CLAP embeddings paired with standard machine learning classifiers: support vector machines (SVMs), random forests, and K-nearest neighbors. The results were striking. An SVM classifier achieved an F1 score of 0.969 for detecting AI music, with precision of 0.958. Even simpler classifiers like random forests reached F1 scores above 0.95. These systems effectively function as an ai music genre detector, except instead of classifying genre, they classify origin: human or machine.
Beyond CLAP, detection systems analyze phase coherence and temporal quantization. Human recordings have high phase entropy, meaning the phase relationships between frequency components are naturally chaotic. AI generators often produce audio with anomalously low phase entropy, creating impossibly perfect phase relationships that do not occur in real acoustic environments. Similarly, human musicians introduce micro-timing variations even in electronic music. AI generators tend to snap transients to a mathematically perfect grid. When the Inter-Beat Interval variance approaches zero, the likelihood of synthetic generation increases significantly.
Audio Fingerprinting Approaches
Rather than analyzing audio after the fact, fingerprinting aims to mark AI-generated content at the source so it can be identified later. Two complementary standards are emerging.
C2PA (Coalition for Content Provenance and Authenticity) attaches cryptographically signed metadata to audio files, documenting authorship, source, licensing rights, and whether AI was involved in production. Google's SynthID takes a different approach: it embeds imperceptible watermarks directly into audio waveforms generated by AI tools, including Google's Lyria music model. These watermarks survive compression, format conversion, and basic audio processing.
The EU AI Act's transparency requirements, becoming enforceable in August 2026, will require AI providers to embed machine-readable watermarks and metadata in generated content. Non-compliance carries fines of up to 15 million EUR or 3% of global annual turnover. This regulatory backstop means the goal is to fingerprint every ai song to identify it at the point of creation, not just detect it downstream.
The practical value of fingerprinting is clear: it does not depend on detecting subtle artifacts that might be obscured by post-processing. If the watermark is embedded at generation time, it persists regardless of what happens to the audio afterward. Tools like the remusic ai music analyzer and similar platforms are beginning to incorporate watermark detection alongside spectral analysis for more comprehensive results.
| Detection Method | What It Analyzes | Strengths | Limitations |
|---|---|---|---|
| Spectral Artifact Analysis | Frequency peaks, MFCC distributions, bark band kurtosis | Over 99% accuracy on known generators; architecture-dependent signals cannot be easily removed | Sensitive to resampling; performance drops when tested on unseen platforms |
| CLAP Embedding Classification | 512-dimensional audio representations in learned feature space | High F1 scores (0.95+); generalizes across musical styles; computationally efficient | May exploit pipeline artifacts (bit rate, sample rate) rather than true AI qualities |
| Phase and Temporal Analysis | Phase entropy, Inter-Beat Interval variance, cross-correlation between stems | Targets physical impossibilities in AI output; hard to fake natural phase chaos | Less effective on electronic music where quantization is intentional |
| Watermark Detection (C2PA/SynthID) | Embedded metadata and imperceptible audio watermarks | Survives compression and format conversion; regulatory backing from EU AI Act | Only works on content generated after watermarking is implemented; does not cover legacy AI tracks |
Each method has blind spots. Spectral analysis struggles with unseen generators. CLAP embeddings may latch onto production pipeline characteristics rather than genuine AI qualities. Temporal analysis loses reliability in genres where quantization is standard practice. Watermarking only covers future content from compliant providers.
This is precisely why enterprise-grade detection requires multi-model ensemble approaches that combine multiple methods simultaneously. No single technique provides bulletproof results. But the real test of any detection system is not how it performs in a controlled lab setting. It is how it holds up against the messy reality of human perception, contextual clues, and the gap between what algorithms catch and what our ears miss entirely.
Human Ears Versus Algorithmic Detection
Algorithms can scan spectral peaks and phase entropy in milliseconds. Your ears cannot. That gap between what machines measure and what humans perceive explains why 97% of listeners fail the detection test, and why knowing how to tell if a song is ai generated requires more than just pressing play.
Why Human Ears Fail at Detection
Your brain is wired to find patterns and fill in gaps. Psychoacoustics researchers call this perceptual completion: when you hear a melody, your auditory cortex predicts what comes next and smooths over minor inconsistencies. A slightly unnatural vocal transition or an overly perfect stereo image gets mentally corrected before you consciously register it. This is the same mechanism that lets you understand speech in a noisy room, but it works against you when trying to spot AI music.
Consider what happens when you ask yourself "does this sound like ai?" You are listening for something obviously wrong: robotic vocals, glitchy artifacts, or unnatural phrasing. Modern generators like Suno and Udio have largely eliminated those surface-level tells. The artifacts that remain exist in frequency ranges and phase relationships that human hearing simply cannot resolve. A systematic evaluation published in Scientific Reports found that even trained models experience significant performance drops when tested on unfamiliar generators, highlighting how subtle and variable these signatures are. If sophisticated algorithms struggle with generalization, casual listeners have virtually no chance.
There is also a familiarity bias at play. Most people evaluate music emotionally: does it make me feel something? AI-generated tracks are trained on millions of songs that already made people feel something. They replicate the harmonic progressions, rhythmic patterns, and production aesthetics that trigger emotional responses. Your brain registers "this sounds good" and stops investigating further. The question of how ai does this sound never arises because the emotional payoff arrives before skepticism kicks in.
Social and Contextual Red Flags
Where ears fail, investigation succeeds. How to tell if music is ai often comes down to looking beyond the audio itself. AI-generated artists leave a trail of contextual inconsistencies that human judgment can catch, even when the music sounds flawless.
Take "The Velvet Sundown," an AI band that accumulated over 1.3 million monthly Spotify listeners before being identified as AI-generated. The music itself passed the ear test for over a million people. What eventually exposed it was contextual investigation: no verifiable band members, no touring history, no behind-the-scenes content, and a release cadence that no human band could sustain.
Here is what to look for when you want to know how to spot ai music through non-audio clues:
- Release velocity — Human artists typically release singles every few weeks at most. AI content farms push multiple tracks daily. If an artist drops 30 songs in a month with consistent production quality, that is a red flag.
- Artist identity gaps — No social media presence, no live performance history, generic or AI-generated profile photos, and vague bios that avoid specific biographical details.
- Catalog consistency without evolution — Human artists develop over time. Their early work sounds different from their latest. AI-generated catalogs often maintain an eerily uniform quality and style from the first release onward.
- Missing collaborator networks — Real musicians credit producers, engineers, session players, and co-writers. AI tracks often list a single creator with no verifiable professional connections.
These contextual signals do not prove AI origin on their own. A bedroom producer releasing instrumental beats might check some of the same boxes. But when multiple red flags stack up simultaneously, the probability shifts heavily toward synthetic generation. How to know if music is ai becomes less about any single indicator and more about the weight of combined evidence.
The most reliable detection approach layers these methods together. Here is how they rank from least to most dependable:
- Casual listening — Unreliable. The 97% failure rate speaks for itself.
- Trained listener analysis — Slightly better. Audio engineers and producers may catch production inconsistencies, but still miss most modern AI output.
- Contextual investigation — Effective for identifying AI content farms and fake artist profiles, though it requires time and cannot scale automatically.
- Algorithmic detection — High accuracy on known generators (95%+ F1 scores), but performance degrades on unseen platforms and post-processed audio.
- Combined approaches — The gold standard. Pairing algorithmic scanning with contextual verification and human review catches what any single method misses.
No single layer is sufficient. A track might pass algorithmic detection because it was generated by a new, unknown model, but fail contextual investigation because the artist profile has no verifiable history. Conversely, a legitimate human artist with a sparse online presence might trigger contextual red flags but pass spectral analysis cleanly. How to tell if a song is ai with confidence means running it through multiple filters and weighing the results together.
This layered reality raises a harder question: do all AI generators leave equally detectable traces, or are some platforms already producing output that slips past every method available?

Do Different AI Generators Leave Unique Traces
Not all AI generators are created equal, and they do not fail in the same ways. Understanding how does ai music generation work at the architectural level reveals why some platforms produce more detectable output than others, and why a detector trained on one generator can completely miss another.
Each platform uses a different neural network architecture to convert compressed audio tokens back into full waveforms. That architecture determines the specific spectral fingerprint left behind. Suno, Udio, and AIVA each rely on distinct decoder designs with different upsampling strides, kernel sizes, and synthesis methods. These choices create predictable, measurable differences in their output, even when the musical content sounds identical to human ears.
Generator-Specific Signatures and Tells
How does ai make music? At a simplified level, most modern generators work in two stages. First, a language-model-like system generates a sequence of compressed audio tokens representing the musical content. Then, a neural codec decoder expands those tokens back into a full-resolution audio waveform. It is this second stage, the decoder, that leaves the most detectable traces.
Research from Deezer's ISMIR 2025 study demonstrated that each decoder architecture produces spectral peaks at mathematically predictable frequency intervals. Encodec, used in systems like Meta's MusicGen, has deconvolution strides of {8, 5, 4, 2}, which create 161 distinct spectral peaks across the frequency spectrum. DAC, used in VampNet, produces a different peak pattern based on its own stride configuration. When researchers trained individual detectors for each generator and visualized the learned weights, clear and distinct peak patterns emerged for DAC, Encodec, and Suno. These patterns function like architectural fingerprints.
The practical differences between platforms are noticeable even in basic audio analysis. Research published in TISMIR found that Suno tracks have a lower average spectral centroid than both Udio and human recordings, suggesting reduced high-frequency content. Suno also exhibits higher bark bands kurtosis, meaning more extreme spectral peaks and sharper transient sounds. Udio, by contrast, produces output that statistically resembles human recordings more closely across multiple audio descriptors. This explains why detection systems trained on Udio generalize well to Suno (F1 scores above 0.94), but models trained only on Suno struggle to detect Udio (F1 scores dropping to 0.63).
If you have spent time on any ai music generator reddit thread, you will have seen users noting that Suno tracks often suffer from audible phasing artifacts, a kind of metallic shimmer in the high frequencies. Udio's output generally sounds cleaner to human ears, which also makes it harder for algorithms to catch. AIVA takes yet another approach, generating music symbolically through MIDI-like representations before rendering audio through sample libraries, which produces fewer of the waveform-level artifacts that spectral detectors target.
How are ai songs made also matters for detection because the generation pipeline determines what artifacts survive. A track generated entirely within Suno carries the full spectral fingerprint of its decoder. But a track where someone uses AI to generate a melody, then re-records it with live instruments, carries almost none. The deeper the AI involvement in the final audio rendering, the stronger the detectable signature.
How Post-Processing Defeats Detection
Here is where detection confidence starts to erode. Standard music production techniques, the same ones every human producer uses, can obscure or destroy the spectral artifacts that detectors rely on.
The Deezer research team's robustness experiments tested their detector against common audio transformations and found dramatic performance drops. Pitch shifting by just two semitones caused detection accuracy to plummet to near zero for some generators. Reencoding in mp3, AAC, or Opus at 64 kbps similarly devastated performance. Even something as simple as resampling audio from 44.1 kHz to 22.05 kHz fooled the commercial IRCAM Amplify detector into misclassifying all Suno samples.
Not all transformations are equally destructive. Time stretching, EQ adjustments, and reverb application left detection largely intact in the same experiments. The pattern suggests that transformations affecting frequency positions (pitch shift, resampling) disrupt spectral peak detection, while transformations that modify amplitude or add reflections (EQ, reverb) do not shift the peaks themselves.
For someone following a suno ai tutorial who wants to make their output less detectable, the recipe is straightforward: pitch shift slightly, resample, reencode at a different bitrate, and mix with human-produced stems. Each step degrades the spectral fingerprint. Stack enough of them together, and current detectors lose confidence entirely. This is not theoretical. It is already happening at scale.
The robustness problem extends to generalization across generator families. A detector trained exclusively on Encodec-based output (like MusicGen) achieves near-zero accuracy when tested on DAC-based output (like VampNet), and vice versa. The spectral signatures are family-specific. A detector must be trained on each generator family separately, or use ensemble methods that cover multiple architectures simultaneously.
| AI Generator | Output Quality Perception | Known Detection Vulnerabilities | Common Use Cases |
|---|---|---|---|
| Suno | Good vocals, noticeable phasing in high frequencies; lower spectral centroid | Detectable spectral peaks from decoder strides; phasing artifacts audible to trained ears; pitch shift and resampling defeat detection | Full song generation from text prompts; viral social media content; rapid prototyping |
| Udio | Higher fidelity; output statistically closer to human recordings across audio descriptors | Harder to detect than Suno; possible architecture change between versions complicates cross-version detection; resampling to 22.05 kHz fools commercial detectors | Higher-quality song generation; music production demos; creative experimentation |
| AIVA | Clean orchestral and instrumental output; uses sample-based rendering rather than neural waveform synthesis | Symbolic generation pipeline avoids many waveform-level artifacts; detection must target compositional patterns rather than spectral signatures | Film scoring; background music; classical and orchestral composition |
| Boomy | Variable quality; suspected symbolic generation with sample sequencing | Only 9% detected by IRCAM Amplify; most detectors trained on Suno/Udio fail entirely on Boomy output | Casual music creation; streaming catalog generation; beginner-friendly production |
The first song sung by ai to reach a national chart appeared in Germany in 2024, demonstrating that AI-generated music is not just a curiosity confined to niche platforms. It is entering mainstream distribution channels where detection systems must operate at scale. Each new generator version and each new platform adds another target that detectors must learn to recognize, while post-processing techniques give motivated users straightforward ways to strip away the very signatures those detectors depend on.
This creates an obvious question: if individual detection methods have known blind spots, and post-processing can defeat them, what tools are actually available for someone who wants to check a specific track right now?
Tools You Can Use to Check for AI Music
Knowing that detection methods exist is useful. Having actual tools you can open in a browser and test a track against right now is better. The landscape of available ai music checker services has expanded rapidly, but not all tools work the same way, target the same signals, or deliver the same reliability. Some scan for spectral fingerprints. Others analyze metadata. A few let you pull a track apart and inspect its components manually.
The practical approach combines two categories: dedicated detection services that give you a probability score, and audio analysis tools that let you dig deeper when a score alone is not enough. Used together, they form the most accessible detection workflow available to independent creators, curators, and curious listeners.
Dedicated AI Music Detection Services
Several ai song checker platforms now offer direct upload-and-scan functionality. Their accuracy varies, their methodologies differ, and understanding what each one actually checks helps you interpret results correctly rather than treating any single score as gospel.
ACRCloud's AI Music Detector uses neural network analysis to detect specific audio artifacts and provides both a probability score and metadata about the audio's origin. It distinguishes human-created from AI-generated tracks, identifies the specific generative model used (Suno, Udio, and others), and can analyze vocals and accompaniment separately. This powers consumer-facing tools like AHA Music, which offers 5 free checks per day and uniquely names the specific generator behind a flagged track.
If you are looking for an ai music detector online free option, here is what is currently available:
- AHA Music (ACRCloud-powered) — 5 free daily checks, supports MP3/WAV/OGG/FLAC/AAC up to 20MB, identifies the specific AI generator by name. The strongest free ai song identifier for quick verification.
- TheGhostProduction AI Detector (ACRCloud) — Same detection engine as AHA Music with a 50MB upload cap, free with no account required. Results mirror AHA since both run on ACRCloud's backend.
- LetsSubmit AI Music Checker — 5 free checks per day, uses MERT transformer embeddings, and publishes its actual holdout accuracy at 87.67%. The most transparent tool about its limitations.
- SubmitHub AI Checker — Free up to 2 checks per session. Trained primarily on Suno and Udio outputs. Curators on the platform rely on this, so it reflects what gatekeepers actually see when evaluating your submission.
- Authio — 5 free daily checks, 100MB upload limit, REST API with Python/Node/Java SDKs. Claims 99.42% accuracy but does not publish the benchmark dataset or methodology behind that number.
- MatchTune (DeepMatch) — Enterprise-only, no self-serve access. Published a benchmark on an 8,000-track test set showing 95% accuracy with 0.01% false positives. Detects across Suno, Udio, Boomy, Riffusion, Mubert, Mureka, and Loudly. Built for streaming services and labels.
A critical caveat: these tools function as an ai music identifier for the specific signals their models were trained on. Testing across multiple checkers reveals that the same track can receive wildly different scores depending on which detection vectors each tool prioritizes. Running two checkers that use different underlying approaches (ACRCloud for spectral analysis, LetsSubmit for transformer embeddings) gives you broader coverage than relying on any single service. Think of each tool as a specialist rather than a generalist. No a.i. detector for music free or paid covers every possible generation method.
Audio Analysis Tools for Deeper Inspection
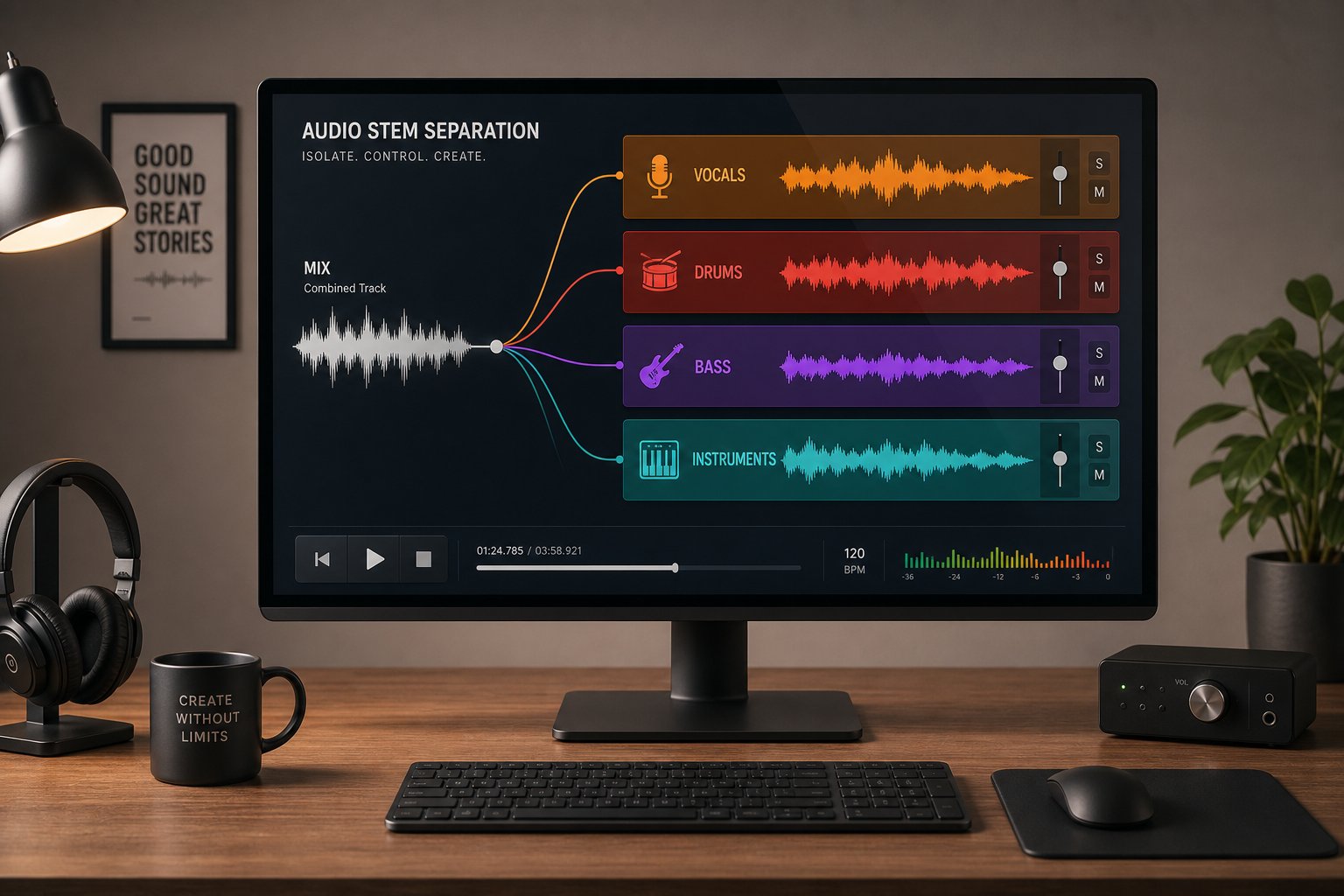
Probability scores tell you something, but they do not tell you everything. When a detection service returns an ambiguous result, say 55% AI confidence, you need a way to investigate further. This is where audio separation and component-level inspection become valuable.
The logic is straightforward: AI-generated tracks often mask artifacts in the full mix that become obvious when you isolate individual stems. A vocal track might sound natural layered over instrumentation, but separated out, you might notice unnatural breath patterns, phase inconsistencies, or stereo imaging that no microphone would produce. Similarly, an AI-generated drum pattern might exhibit perfect quantization that only becomes apparent when stripped of the melodic elements masking it.
Stem separation tools let musicians, students, and remixers pull a suspicious track into its component layers — vocals, drums, bass, guitar, accompaniment — and examine each one independently. This hands-on inspection catches production inconsistencies that full-mix listening misses entirely. You are essentially using the same technique a forensic audio analyst would: isolate the elements and look for what does not belong.
Tools that support this deeper inspection workflow include:
- MakeBestMusic Audio Separator — Separates tracks into individual stems for manual inspection. Useful as a practical first step when you want to examine vocals, instruments, and production elements individually. Isolating components reveals AI artifacts hidden in the full mix, making it a hands-on complement to automated detection scores.
- ACRCloud Vocal & Accompaniment Analysis — Analyzes the full track plus separated vocal and accompaniment parts independently, detecting AI generation within each layer rather than only the combined mix.
- DAW-based spectral analysis — Tools like iZotope RX or Adobe Audition let you visually inspect spectrograms of separated stems, looking for the telltale grid-like artifacts and unnaturally smooth frequency distributions that AI generators produce.
The combination works like this: run a track through a dedicated ai music finder service to get an initial probability score. If the result is ambiguous or you need deeper confidence, separate the track into stems and inspect each layer for the spectral and temporal artifacts described in the technical detection methods above. A sample finder ai approach can also help identify whether specific elements within a track were lifted from AI-generated sample libraries rather than recorded or synthesized by a human producer.
This two-layer workflow, automated scoring plus manual stem inspection, catches more than either approach alone. It is particularly effective for hybrid tracks where some elements are human-produced and others are AI-generated, a scenario that single-score detectors handle poorly.
Of course, every tool in this list works against the current generation of AI output. The generators are not standing still. Each model update aims to reduce exactly the artifacts these tools target, creating a moving target that no static detection method can permanently solve.
The Arms Race Between Generation and Detection
Every detection tool described above works against a snapshot in time. The generators are not frozen targets. They update, retrain, and refine their architectures specifically to reduce the artifacts that detectors exploit. Meanwhile, detection researchers respond with deeper analysis methods targeting patterns that surface-level fixes cannot eliminate. This back-and-forth defines the current state of music and ai: a moving equilibrium where neither side holds a permanent advantage.
Can ai make better music than humans? That question misses the point. The real competition is not between AI and human creativity. It is between AI systems learning to sound indistinguishable from human output and detection systems learning to see through the disguise. Each improvement on one side forces adaptation on the other, and the cycle accelerates with every model release.
How Generators Are Learning to Evade Detection
When researchers publish findings about detectable spectral peaks or phase inconsistencies, generator developers take note. The next model version often addresses exactly those weaknesses. This is not speculation. The progression from early Suno versions (which produced obvious phasing artifacts users openly discussed on Reddit) to current releases (which sound substantially cleaner) demonstrates active refinement aimed at reducing detectable signatures.
The evasion strategies operate at multiple levels:
- Architecture refinement — Changing decoder stride configurations, kernel sizes, and upsampling methods shifts the spectral peak patterns that detectors were trained to recognize. A detector calibrated for one architecture version may fail entirely on the next.
- Training data expansion — Broader, more diverse training corpora produce output with greater statistical variation, making it harder for classifiers to find consistent signatures across all generated tracks.
- Adversarial training — Some generators incorporate detection models directly into their training loop. The generator learns to produce output that specifically fools the detector, similar to how GANs pit a generator against a discriminator.
- Post-processing integration — Newer platforms apply automatic mastering, resampling, and format conversion as part of their pipeline, stripping away artifacts before the user ever downloads the file.
The TISMIR research on AI music detection demonstrated this vulnerability concretely. Simply resampling audio from 44.1 kHz to 22.05 kHz caused the commercial IRCAM Amplify detector to misclassify all Suno samples. That is not a sophisticated attack. It is a single command-line operation. When trivial transformations defeat commercial-grade detection, imagine what deliberate architectural changes accomplish. New ai songs from updated models may carry none of the signatures that current tools target.
The generalization problem compounds this. Detectors trained on Suno and Udio achieved F1 scores above 0.95 on those platforms, but when tested on Boomy, a different AI music platform, detection rates collapsed. IRCAM Amplify identified only 9% of Boomy tracks as AI-generated. The researchers' own SVM classifier caught just 4%. A detector that works brilliantly on known generators becomes nearly useless against unfamiliar ones. Every new platform that launches, every major version update, potentially resets the detection clock.
The Detection Research Response
Detection researchers are not simply retraining the same models on new data. The response involves fundamentally different analytical approaches that target deeper structural patterns, ones that cannot be eliminated without degrading the music itself.
One promising direction is the shift from surface-level spectral analysis to structural and compositional detection. Rather than looking for frequency peaks that a decoder leaves behind, these methods analyze musical form, harmonic development, and long-range temporal dependencies. The SpecTTTra architecture splits spectrograms into temporal and spectral components processed through a transformer with global attention, capturing long-range dependencies that simpler models miss. While its current performance is uneven, the approach points toward detection methods that analyze what the music does over time rather than what artifacts it carries in any single frame.
Neural fingerprinting represents another evolution. Companies like SoundPatrol, emerging from Stanford's AI Lab, map music into high-dimensional embedding spaces that capture melodic contour, harmonic progression, rhythmic feel, and timbral characteristics simultaneously. This perceptual fingerprinting does not depend on detecting codec artifacts. It understands musical meaning, identifying structural similarity even when every surface-level feature has changed. The system can flag tracks that carry the creative DNA of protected works regardless of whether they were pitch-shifted, remastered, or generated by an unknown model.
Multi-modal detection is also gaining traction. Instead of relying solely on audio analysis, next-generation systems combine spectral scanning with metadata verification, release pattern analysis, and cross-platform behavioral signals. A track might pass spectral analysis cleanly but get flagged because the uploading account exhibits patterns consistent with AI content farms: rapid release cadence, no social verification, and distribution across dozens of streaming services simultaneously.
The regulatory layer adds another dimension. The EU AI Act's transparency requirements, enforceable from August 2026, mandate machine-readable watermarks in AI-generated content. If watermarking becomes standard at the generation layer, detection shifts from forensic analysis to simple verification: check for the watermark. Generators that strip watermarks face legal consequences rather than just technical countermeasures. This moves part of the arms race from a purely technical domain into a legal one, where the no ai music position gains enforceable backing.
No single detection method will remain permanently reliable. The relationship between generation and detection is adversarial by nature. What works today exploits artifacts that tomorrow's models are already being trained to eliminate.
This is why ai music updates matter for anyone relying on detection results. A tool that scored 99% accuracy six months ago may have degraded significantly against current-generation output. The researchers behind the TISMIR study framed this explicitly: their work investigates the meaningfulness of AI music detection as a task, not a solved problem. They found that high performance on known platforms tells you almost nothing about performance on unknown ones. The field is not converging on a solution. It is locked in an ongoing cycle where each side's improvements force the other to adapt.
For creators and platforms, the practical implication is clear: detection workflows must be treated as living systems that require regular updates, not one-time implementations. Any claim of permanent, universal detection accuracy should be met with skepticism. The landscape where ai music is cooked into every playlist and release queue demands continuous vigilance rather than static tooling.
This adversarial dynamic gets even more complicated when you consider that most real-world music does not fall neatly into "human" or "AI" categories. The growing middle ground, where human creativity and AI assistance blend in varying proportions, creates detection challenges that neither side of the arms race has adequately addressed.
The Gray Area of Human-AI Music Collaboration
Most detection conversations assume a binary: either a track is fully human or fully AI. Reality is messier. A songwriter might use an ai songwriting app to generate chord progressions, then write original lyrics and record live vocals over the top. A producer might record a full band performance, then use AI-powered tools to replace a weak drum take or add a background to a music performance on ai-generated orchestral layers. Where does "human-made" end and "AI-generated" begin?
This gray area is where detection breaks down most completely. The hybrid production model has become standard practice among working composers in sync licensing, production music, and film scoring. Professional workflows routinely combine AI-generated rhythmic foundations and harmonic seeds with human arrangement decisions and live performance layers. The result is music that contains both human and synthetic DNA in proportions that vary from track to track, sometimes from section to section within the same song.
Where Human Creativity Meets AI Assistance
Imagine a spectrum. On one end, a guitarist writes, performs, records, mixes, and masters everything by hand. On the other, someone types a prompt into Suno and downloads the result unchanged. Between those extremes lies an enormous range of workflows that most creators now occupy.
Common hybrid scenarios include:
- AI beat generation with original lyrics and vocals (Detection difficulty: Moderate) — The instrumental stems carry AI spectral signatures, but the vocal track is authentically human. Stem-level analysis can potentially identify the split, but the full mix blurs the boundary.
- AI-assisted mastering of human performances (Detection difficulty: Very low) — Tools like LANDR or iZotope's AI mastering apply algorithmic processing to human recordings. The underlying performance is entirely human; only the final polish is automated. No current detector flags this.
- AI melody generation re-recorded with live instruments (Detection difficulty: Near impossible) — A composer uses AI to generate a melodic idea, then performs it on a real piano or guitar. The final audio contains zero AI waveform artifacts because the sound was produced acoustically. Only compositional analysis might catch unusual harmonic patterns.
- AI stem replacement in otherwise human compositions (Detection difficulty: Moderate to high) — A band records a full track but replaces the bass part with an AI-generated stem that better fits the mix. One layer is synthetic; the rest are human. Detection depends entirely on whether the replacement stem carries identifiable artifacts.
- AI vocal synthesis over human-produced instrumentals (Detection difficulty: Moderate) — Producers use voice cloning or AI vocal generators to create singing performances over beats they produced themselves. Knowing how to detect ai generated voice becomes critical here, as the vocal stem is the only synthetic element.
- AI-generated bands with human post-production (Detection difficulty: Variable) — Some ai generated bands start with fully AI output but apply extensive human mixing, editing, and arrangement decisions. The 50 stems mix edits music ai process ai powered workflow means the final product is a genuine collaboration between algorithm and human judgment.
The proven hybrid workflow used by library composers follows a structured process: generate a foundation using AI, export stems at high resolution, import into a DAW, add human performance layers, edit structure manually, then mix and master professionally. The output is neither purely human nor purely AI. It is something in between that defies simple categorization.
People often ask what ai makes the best song lyrics, but the more relevant question for detection is whether AI-generated lyrics paired with a human vocal performance constitute "AI music" at all. The audio itself carries no synthetic artifacts. The creative contribution is split. Platforms have no consistent answer.
Can Partial AI Use Be Detected
The technical challenge is significant. Detection systems designed to output a binary "AI or human" verdict struggle with hybrid content because the signals conflict. The multi-model detection framework proposed by researchers addresses this by outputting a confidence index from 0 to 10 rather than a yes/no answer. A score of 5 to 6 indicates "ambiguous or AI-assisted," acknowledging that the system detected certain AI-like features in some elements while others appear human.
Stem separation is the most promising approach for partial detection. By splitting a track into vocals, drums, bass, and other instruments, specialized detectors can analyze each layer independently. If the vocal stem passes an ai lyric detector and voice authenticity check while the instrumental stems trigger AI flags, the system can infer a hybrid workflow. Research confirms that including background music context actually improves fake singing detection accuracy, suggesting that the relationship between stems carries forensic information beyond what each stem reveals alone.
But even stem-level analysis has limits. How to tell if a voice is ai generated becomes nearly impossible when the voice was cloned from the artist's own recordings with their consent, or when AI was used only to correct pitch and timing in an otherwise human performance. The line between "AI-assisted" and "AI-generated" is not a technical boundary. It is a philosophical one that platforms must define through policy rather than detection alone.
Current platform policies reflect this confusion. Spotify uses DDEX metadata to let artists disclose where AI played a role, whether in vocals, instrumentation, or post-production. Apple Music requires labels to tag AI involvement but leaves the definition of "AI-generated" to distributors. YouTube treats audio created "largely by AI with minimal human involvement" as potentially low-value content eligible for removal, but does not define what "largely" means in practice. Bandcamp bans music "produced entirely or mainly by AI" without specifying the threshold between "mainly" and "partially."
According to U.S. Copyright Office guidance, fully AI-generated music is not copyrightable, but hybrid works are eligible when there is meaningful human authorship. That legal distinction matters enormously for creators, yet "meaningful human authorship" remains undefined in quantitative terms. Is singing over an AI beat enough? Is choosing which AI-generated take to use enough? Nobody has a definitive answer.
For creators working in hybrid workflows, the practical reality is this: binary detection tools will either miss your AI involvement entirely (if the human elements dominate) or flag your work incorrectly as fully AI (if the synthetic elements happen to trigger the detector's thresholds). Neither outcome reflects the truth of how the music was made. The detection field needs to evolve from asking "is this AI?" to asking "how much AI, and where?" That shift requires not just better algorithms but better frameworks for interpreting what the algorithms find.
This ambiguity in hybrid detection is exactly why a single tool or a single scan is never enough. Building a reliable workflow means layering multiple approaches, from automated scoring to manual stem inspection, and interpreting results with an understanding of what each method can and cannot see.

Building a Reliable AI Music Detection Workflow
Hybrid workflows, evolving generators, and imperfect tools all point to the same conclusion: no single method answers the question of how to detect ai music with full confidence. What works is layering multiple approaches into a repeatable process that accounts for each method's blind spots. Whether you are a listener trying to check if a song is ai generated, a creator defending the authenticity of your work, or a platform operator screening thousands of uploads, the workflow below adapts to your needs.
Practical Steps for Listeners and Creators
Start with what costs nothing: context. Before running any tool, investigate the artist. Do they have a verifiable identity, a touring history, social media presence with behind-the-scenes content? A detected song often reveals itself through non-audio signals first. If the contextual picture looks suspicious, move to automated scanning. If it checks out, you may not need to go further.
For creators submitting to platforms or curators, the stakes are different. You need to know how to tell ai music from human-made content not just to spot fakes, but to ensure your own work does not trigger false positives. Running your tracks through the same detection tools that curators use (SubmitHub's checker, ACRCloud-powered services) before submission lets you catch potential flags early and address them proactively.
When automated scores return ambiguous results, stem separation becomes your most hands-on investigative step. Pulling a track apart into vocals, drums, bass, and instruments exposes artifacts that hide in the full mix. Unnatural breath timing in an isolated vocal, impossibly perfect quantization in a drum stem, or synthetic phase relationships in an instrument layer all become audible once you strip away the masking effect of the combined arrangement. This is how to identify ai music at the component level rather than relying on a single confidence score.
Building Your Detection Workflow
The most reliable results come from combining social investigation, algorithmic tools, and audio analysis into a structured process. Here is a step-by-step workflow you can follow to check if a song is ai or human-made:
- Contextual investigation — Check the artist's identity, release history, social presence, and collaborator credits. Multiple red flags (no live history, rapid release cadence, generic bio) increase the probability of AI origin.
- Automated detection scan — Upload the track to at least two detection services that use different underlying methods (e.g., ACRCloud for spectral analysis and LetsSubmit for transformer embeddings). Compare scores rather than trusting any single result.
- Stem separation and inspection — Use MakeBestMusic's Audio Separator to split the track into individual stems. Listen to each layer independently, paying attention to vocal naturalness, timing consistency, and stereo imaging. AI artifacts that disappear in a full mix often become obvious in isolation.
- Spectral visualization — Open separated stems in a spectral analysis tool and look for unnaturally smooth frequency distributions, grid-like patterns above 16 kHz, or abrupt frequency cutoffs that indicate synthetic generation.
- Cross-reference and weigh evidence — Combine findings from all previous steps. A track that passes contextual checks, returns low AI probability scores, and shows natural characteristics in separated stems is almost certainly human-made. A track that fails multiple layers warrants skepticism regardless of how good it sounds.
This layered approach works because each step catches what the others miss. Contextual investigation identifies content farms that produce clean-sounding audio. Automated tools catch spectral signatures invisible to human ears. Stem separation reveals per-layer inconsistencies that full-mix analysis overlooks. Together, they form the most comprehensive answer available to anyone asking how to know if a song is ai.
No workflow is permanent. Generators improve, detection tools update, and platform policies shift. Treat this process as a living system. Revisit your tools quarterly, test them against current-generation output, and adjust thresholds as the landscape evolves. The question of whether AI music can be detected does not have a static answer. It has a current answer, and staying informed is the only way to keep that answer accurate.